一、概述
1.为什么要排序
查找是计算机应用中必不可少并且使用频率很高的一个操作。在一个排序表中查找一个元素,要比在一个无序表中查找效率高得多。所以为了提高查找效率,节省CPU时间,需要排序。
2.什么是排序
所谓排序,就是整理表中的数据几素,使之按儿素的关键字递增/递减的顺序排列。
3.排序的稳定性
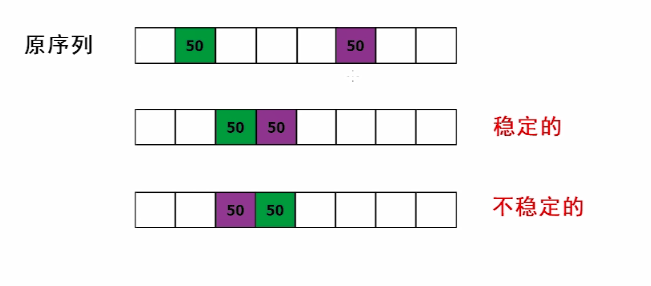
当待排序元素的关键字不相同时,排序的结果是唯一的。如果待排序的表中,有多个关键字相间的元素:经过排序后这些共有相同关键字的元素之间的相对次序保持不变,则称这种排序方法是稳定的;反之,若具有相同关键字的元素之间的相对次序发生变化,则称这种的方法是不稳定的。
4.排序稳定性的意义
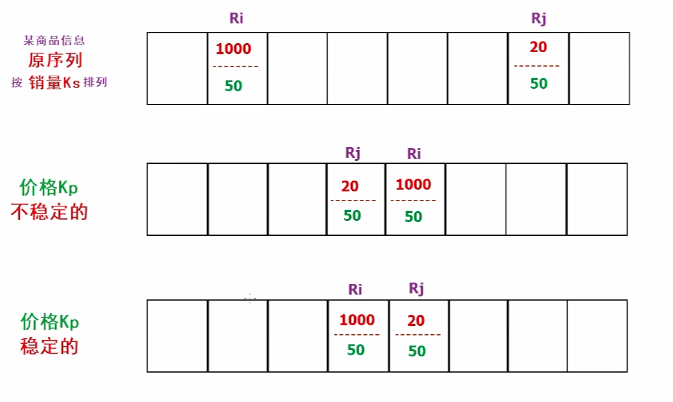
什么时候需要稳定的排序方法?什么时候不需要呢? 考虑一下这种情况: 原序列按关键字Ki排列,现在要求按关键字Km排列,期望:在结果序列中,关键字Km相同的记录按原关键字Ki排列!! “主关键字相同,按原次关键字排列”
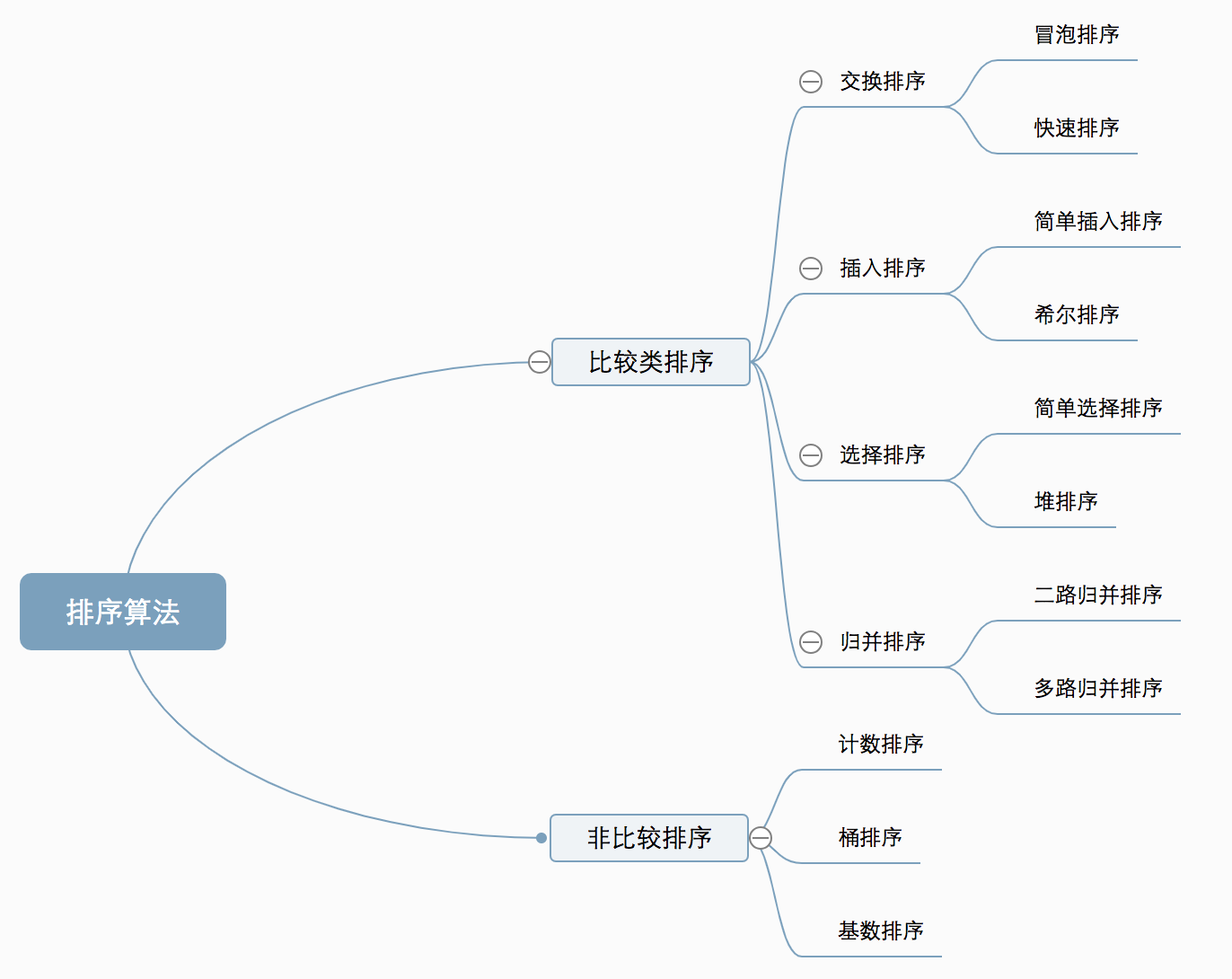
5.排序方法分类
(1)分类方法一
我们根据待排序的数据元素是否全部在内存中,我们把排序方法,分为两类: 内排序:整个排序元素都在内存中处理,不涉及内、外存的数据交换。 外排序:待排序元素有一部分不在内存(如:内存装不下)

(2)分类方法二
- 比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此也称为非线性时间比较类排序。
- 非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此也称为线性时间非比较类排序。
6.排序算法性能评估
(1)算法的时间复杂度 评估一下算法 运行时间 T(n)=O(f(n))
(2)算法的空间复杂度 评估一下算法 所用空间 s(n)=O(f(n))
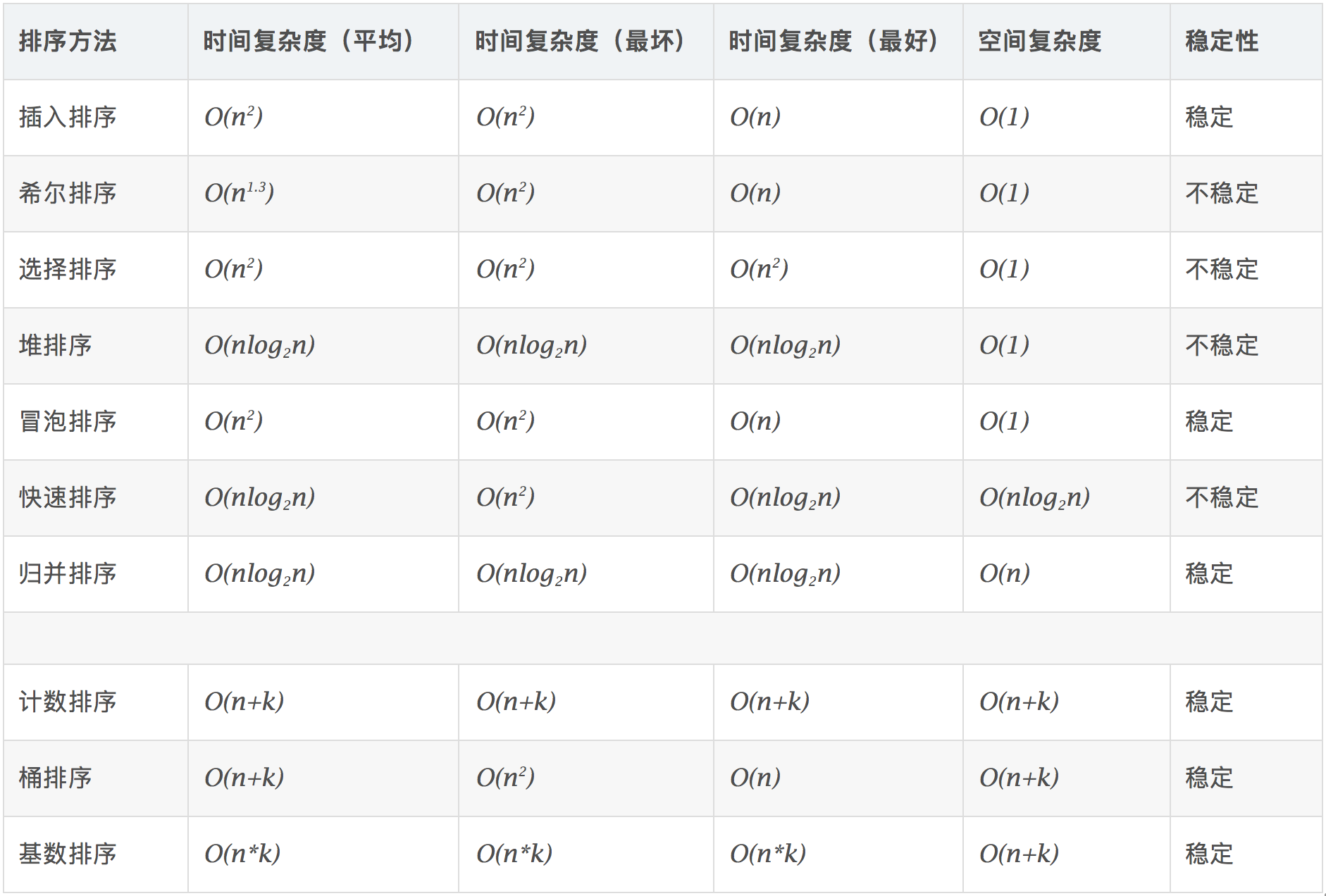
7.相关概念总结
- 稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。
- 不稳定:如果a原本在b的前面,而a=b,排序之后 a 可能会出现在 b 的后面。
- 时间复杂度:对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律。
- 空间复杂度:是指算法在计算机内执行时所需存储空间的度量,它也是数据规模n的函数。
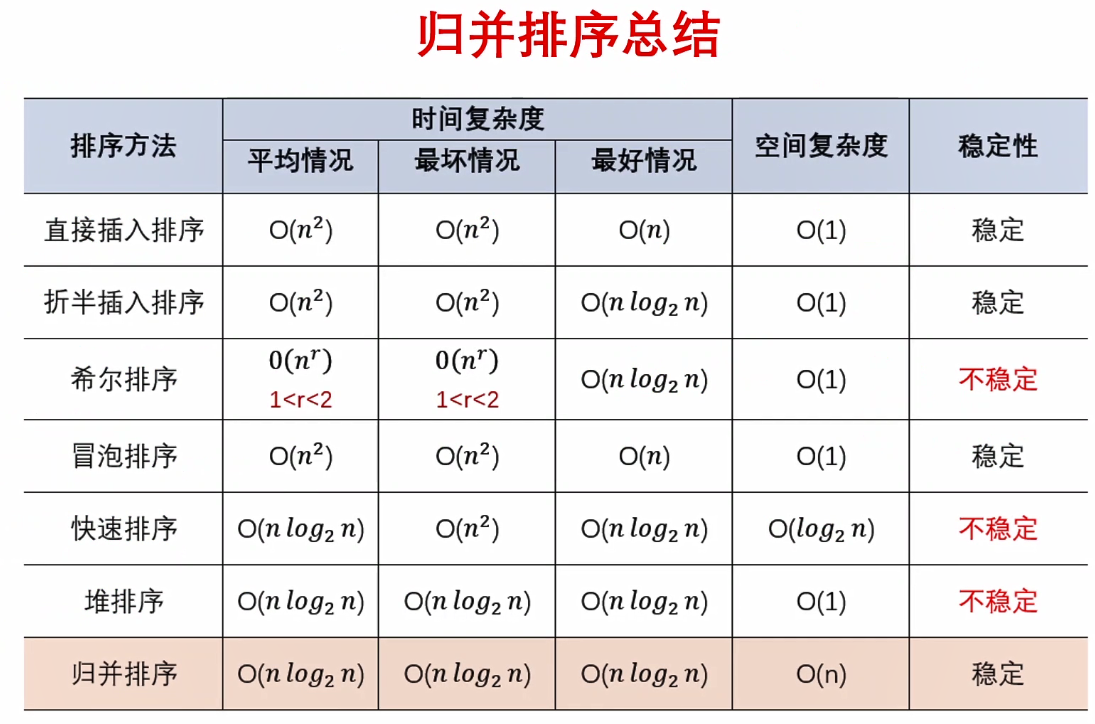
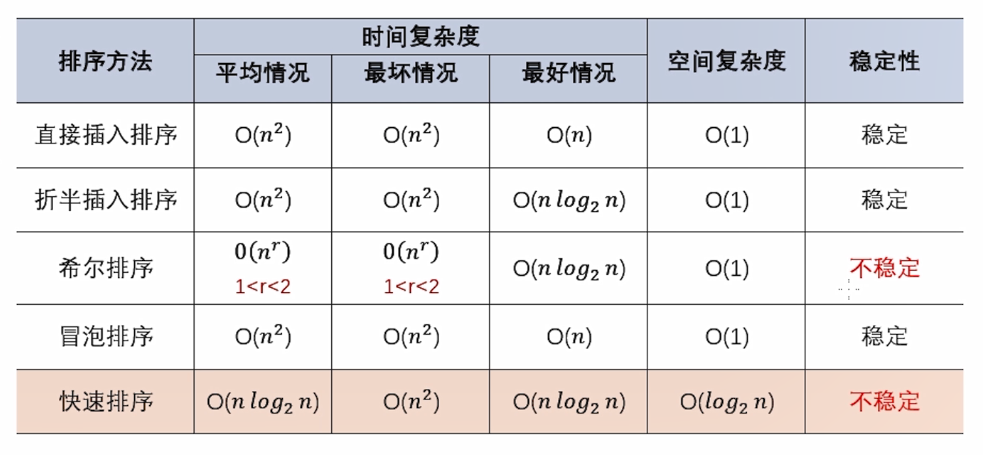
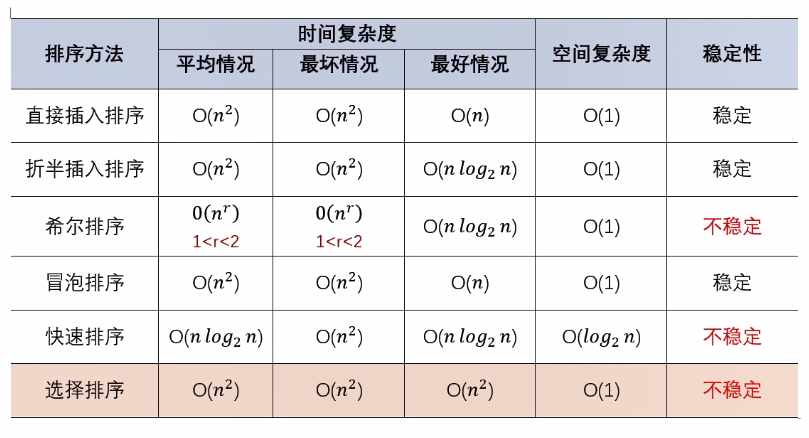
排序算法可以分为内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。常见的内部排序算法有:插入排序、希尔排序、选择排序、冒泡排序、归并排序、快速排序、堆排序、基数排序等。用一张图概括:
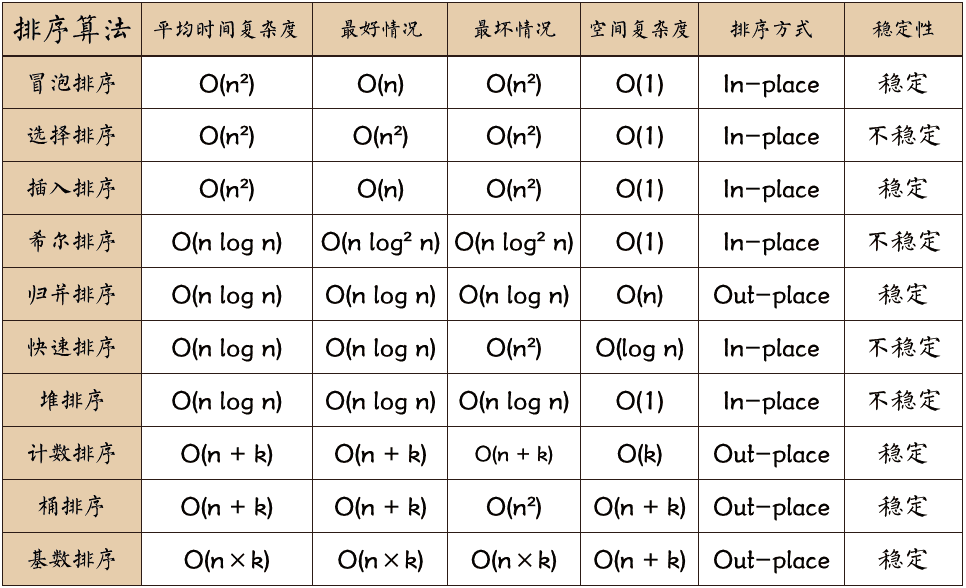
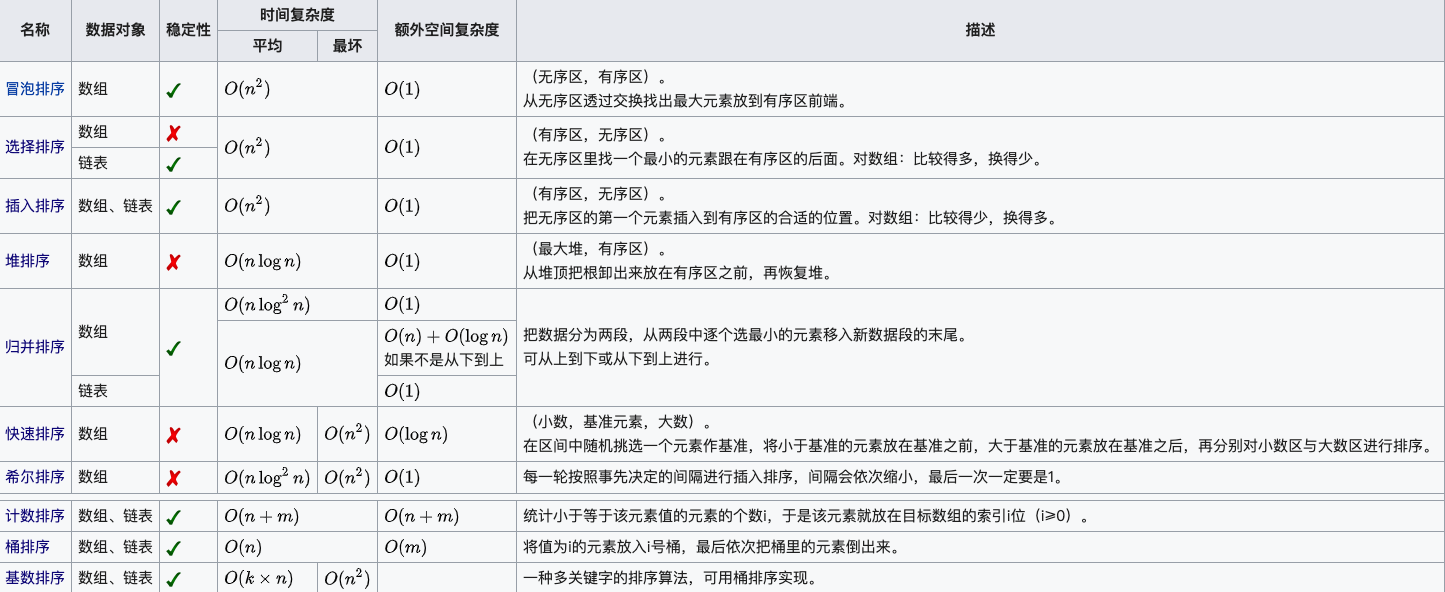
关于时间复杂度
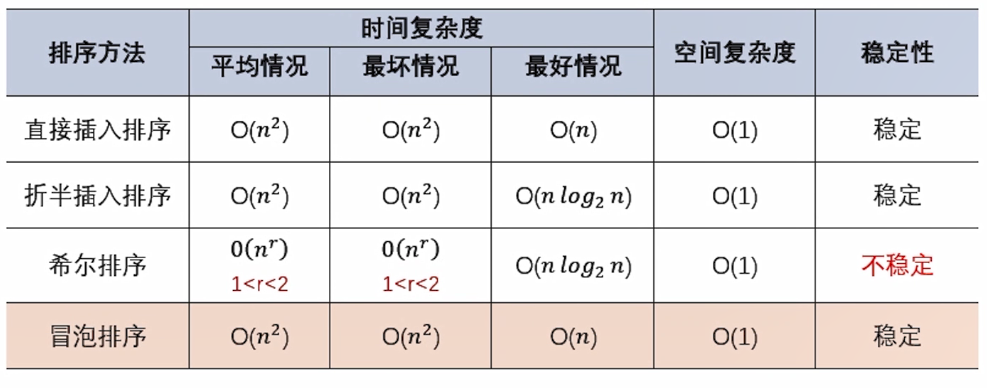
平方阶 (O(n2)) 排序 各类简单排序:直接插入、直接选择和冒泡排序。
线性对数阶 (O(nlog2n)) 排序 快速排序、堆排序和归并排序;
O(n1+§)) 排序,§ 是介于 0 和 1 之间的常数。 希尔排序
线性阶 (O(n)) 排序 基数排序,此外还有桶、箱排序。
关于稳定性
稳定的排序算法:冒泡排序、插入排序、归并排序和基数排序。
不是稳定的排序算法:选择排序、快速排序、希尔排序、堆排序。
名词解释:
- n:数据规模
- k:"桶"的个数
- In-place:占用常数内存,不占用额外内存
- Out-place:占用额外内存
- 稳定性:排序后 2 个相等键值的顺序和排序之前它们的顺序相同
二、直接插入排序
1.定义
(基本思想)每次将一个待排序的元素,按其关键字大小插入到已经排好序的子表中的适当位置,直到全部元素插入完成为止。 直接插入排序<<< 折半插入排序 希尔排序|
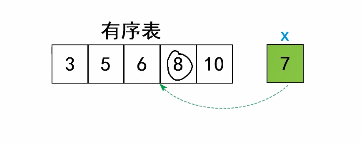
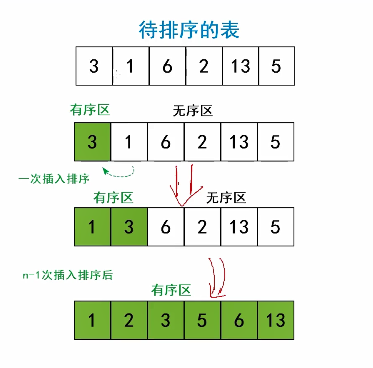

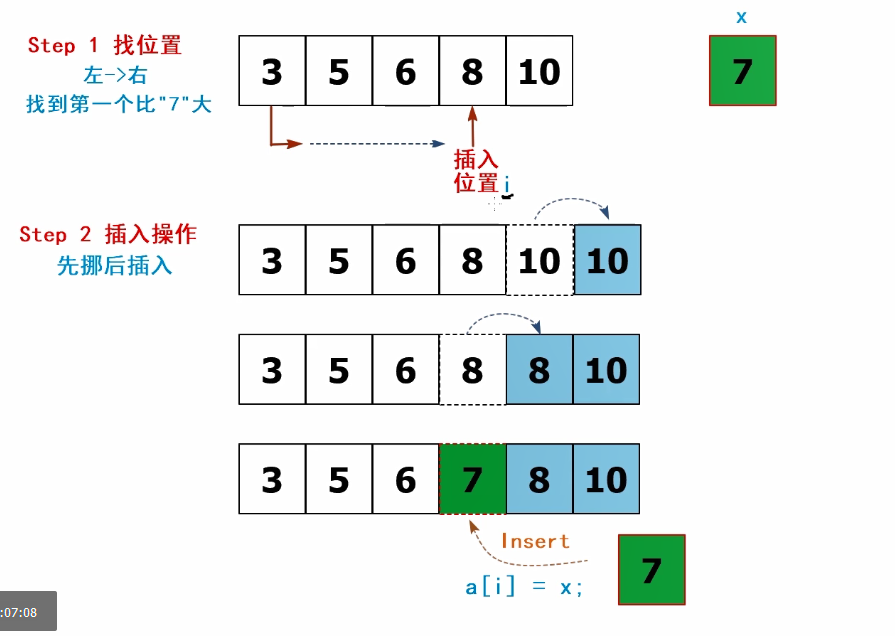
2.基本思路
step1:找插入位置
从第一个元素开始,找到第一个比待插入元素大的元素, “插入位置”I
step2:插入操作
从最后面,一个一个元素往后挪
代码实现
#include <stdio.h>
#define N 10
/*
insert:把元素x,插入到升序数组a[]中去
a[0] a[1] ... a[n-1]
@a:数组名
@n:原有序表的元素个数,0,...,n-1
@x:待插入元素
返回值:
无返回
*/
void insert(int a[], int n, int x)
{
int i,j,k;
//step1:找插入位置
for(i = 0;i < n; i++)
{
if(a[i] > x)
{
break;
}
}
//i就是插入位置
//step: 插入操作(先挪后插入)
for(j = n-1; j >= i;j--)
{
a[j+1] = a[j];
}
a[i] = x;
}
//给数组a[n]进行 直接插入排序
void insertSort(int a[], int n)
{
int i;
for(i = 1; i < n; i++)
{
insert(a, i, a[i]);
}
}
int main()
{
int a[N];
int i;
for(i = 0;i < N; i++)
{
scanf("%d",&a[i]);
}
insertSort(a, N);
for(i = 0;i < N; i++)
{
printf("%d ",a[i]);
}
printf("\n");
return 0;
}3.直接插入改进
“边比较边挪位置” 从最后面的元素,一个一个与待插入元素x比较
[ai] > x => 把[ai]往后挪
a[i+1]-a[i] 直到a[i] <= x此时i+1就是插入位置。
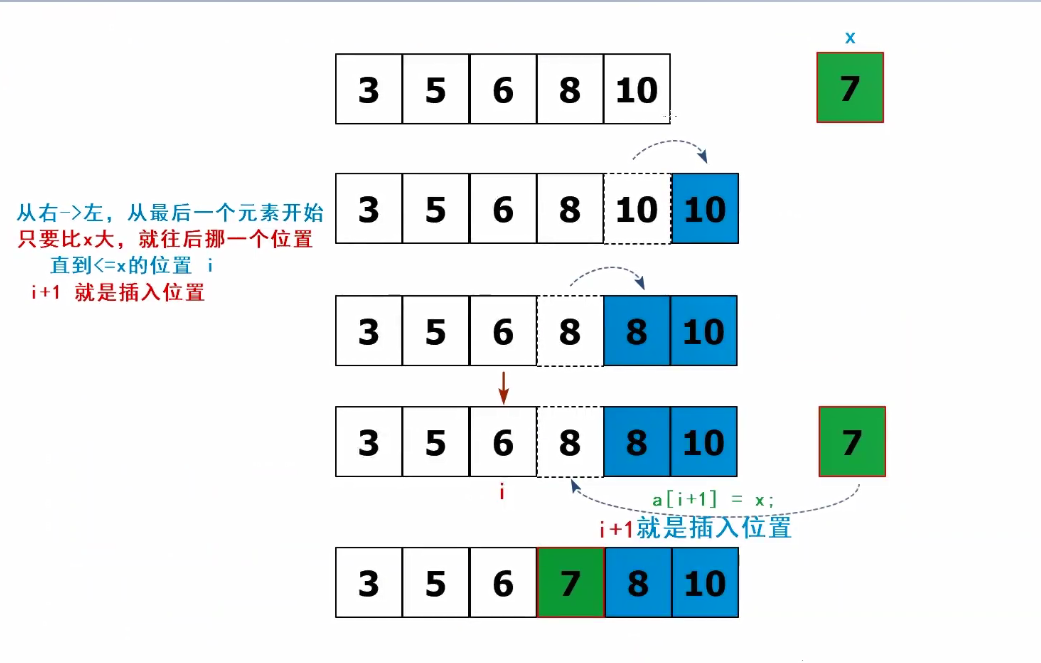
(1)龙哥改进版
#include <stdio.h>
#define N 5
/*
insert:把元素x,插入到升序数组a[]中去
a[0] a[1] ... a[n-1]
@a:数组名
@n:原有序表的元素个数,0,...,n-1
@x:待插入元素
返回值:
无返回
*/
void insert(int a[], int n, int x)
{
int i,j,k;
//debug
printf("\n------------------------------------\n");
for(i = 0; i < n; i++)
{
printf("%d ",a[i]);
}
printf(" \033[1;34m%d\033[0m\n",x); //高亮打印
for(k = n-1; k >= 0 && a[k] > x;k--)
{
a[k+1] = a[k];
}
a[k+1] = x; //k+1就是插入位置
//debug
printf("\n------------------------------------\n");
for(i = 0; i < n+1; i++)
{
if(i == k+1)
{
printf("\033[1;34m%d\033[0m ",a[i]); //高亮打印
}
else
{
printf("%d ",a[i]);
}
}
printf("\n------------------------------------\n");
}
//给数组a[n]进行 直接插入排序
void insertSort(int a[], int n)
{
int i;
for(i = 1; i < n; i++)
{
insert(a, i, a[i]);
}
}
int main()
{
int a[N];
int i;
for(i = 0;i < N; i++)
{
scanf("%d",&a[i]);
}
insertSort(a, N);
for(i = 0;i < N; i++)
{
printf("%d ",a[i]);
}
printf("\n");
return 0;
}(2)改进版集成
#include <stdio.h>
#define N 5
void InsertSot(int a[] , int n)
{
int i,j;
for(i=1;i<n;i++)
{
for(j=i-1;j>=0 && a[j]>a[i];j--)
{
a[j+1] = a[j];
}
a[j+1] = a[i];
}
}
int main()
{
int a[N]={0};
int i;
for(i=0;i<N;i++)
{
scanf("%d",&a[i]);
}
InsertSot(a,N);
for(i=0;i<N;i++)
{
printf("%d",a[i]);
}
printf("\n");
return 0;
}(3)课外集成版
/*插入排序是把一个记录插入到已排序的有序序列中,使整个序列在插入该记录后仍然有序。插入排序中较简单的种方法是直接插入排序,其插入位置的确定方法是将待插入的记录与有序区中的各记录自右向左依次比较其关键字值的大小。*/
/*基本有序,记录数少*/
/*
基本思想: 每一步将一个待排序的元素,按其排序码的大小,插入到前面已经排好序 的一组元素的合适位置上去,直到元素全部插完为止。
直接插入排序; 当插入第i(i>=1)个元素时,前面的array[0],array[1],…,array[i-1]已经 排好序,此时用array[i]的排序码与array[i-1],array[i-2],…的排序码顺序 进行比较,找到插入位置即将array[i]插入,原来位置上的元素顺序后移
元素集合越接近有序,直接插入排序算法的时间效率越高 最优情况下:时间效率为O(n) 最差情况下:时间复杂度为O(n^2) 空间复杂度:O(1),它是一种稳定的排序算法
*/
#include <stdio.h>
void InsertSort(int k[], int n)
{
int i, j, temp;
for( i=1; i < n; i++ )
{
if( k[i] < k[i-1] )
{
temp = k[i];
for( j=i-1; k[j] > temp; j-- )
{
k[j+1] = k[j];
}
k[j+1] = temp;
}
}
}
int main()
{
int i, a[10] = {5, 2, 6, 0, 3, 9, 1, 7, 4, 8};
InsertSort(a, 10);
printf("排序后的结果是:");
for( i=0; i < 10; i++ )
{
printf("%d", a[i]);
}
printf("\n\n");
return 0;
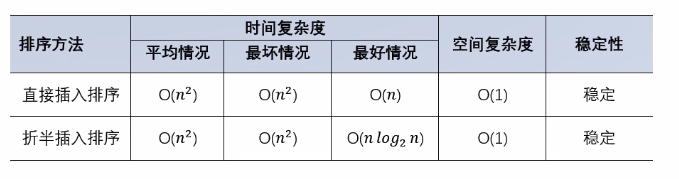
}4.直接插入排序的性能分析
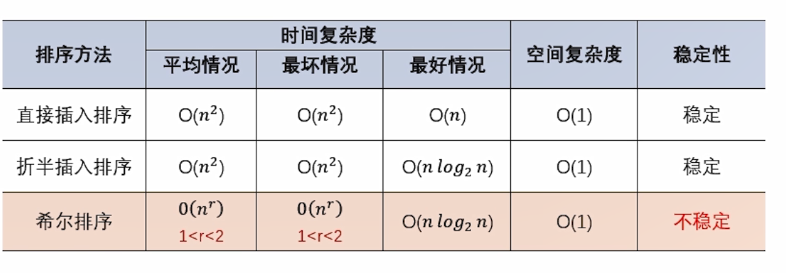
(1)时间复杂度
a.最坏情况
每次来的都是“最小元素” “反序”
O(n2)

b.最好情况
每次来的都是”最大元素” 正序
O(n)

c.平均情况
O(n2)

(2)空间复杂度
O(1)
5.直接插入排序稳定性分析
直接插入排序 是 稳定的。
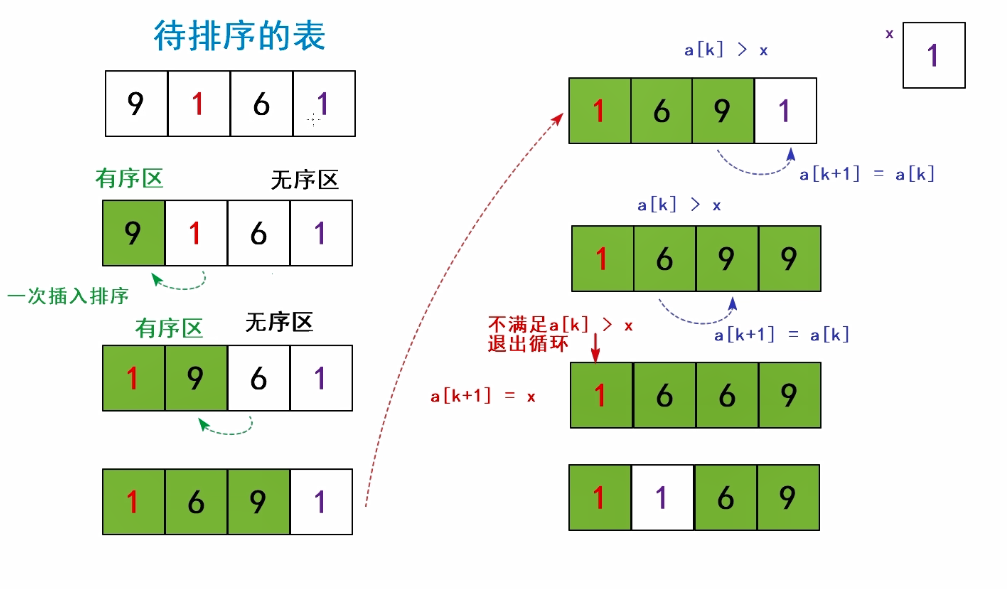
6.总结
1.插入排序在对几乎已经排好序的数据操作时,效率高,可以达到线性排序的效率。O(n)
但
2.插入排序一般来说是低效的,因为插入排序每次只能将数据移动一个位置。
适用场景
插入排序由于O( n2 )的复杂度,在数组较大的时候不适用。但是,在数据比较少的时候,是一个不错的选择,一般做为快速排序的扩充。例如,在STL的sort算法和stdlib的qsort算法中,都将插入排序作为快速排序的补充,用于少量元素的排序。又如,在JDK 7 java.util.Arrays所用的sort方法的实现中,当待排数组长度小于47时,会使用插入排序。

三、折半插入排序
1.什么是折半插入排序
(Binary Insertion Sort)折半插入排序又称二分插入排序,是插入排序的一种。 折半插入排序是对直接插入排序的一种改进。 改进? (直接插入排序)线性查找 —> 折半查找
减少比较次数
基本思路: 每次插入操作,采用折半查找的方式,查找插入位置,
然后再插入元素(先挪后插入)。
2.算法思路
step 1:找插入位置(Insertion Position)
待查找范围的下标 [low,high] 每次跟中间元素PK mid=(low+hiqh)/ 2
根据PK结果,调整待查找范围(改变low or high)
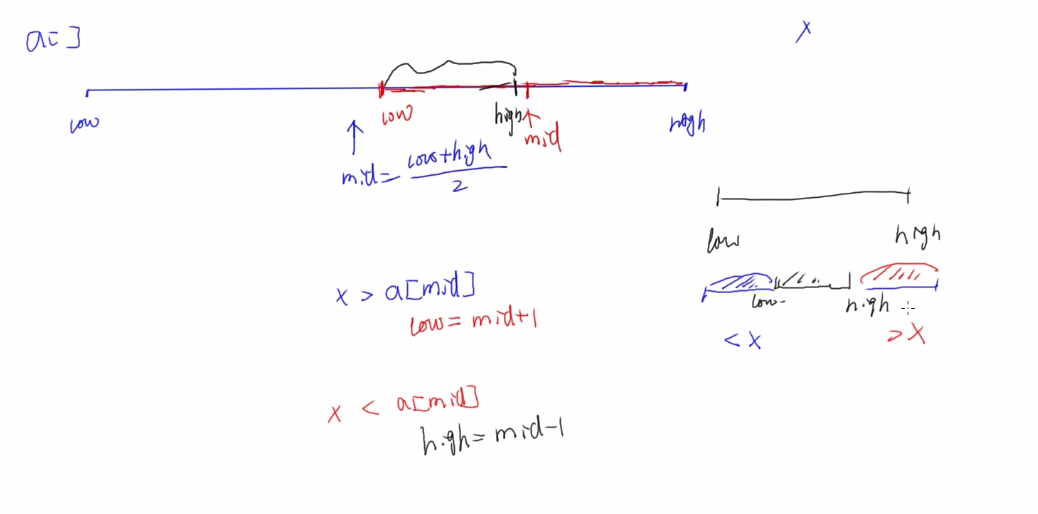
如此重复,直到查找不成功(1ow>high了)或 查找到?
(1)查找不成功
(原有序表中没有待插入的元素)时,插入位置的确定
Insertion Position = high + 1 (low)
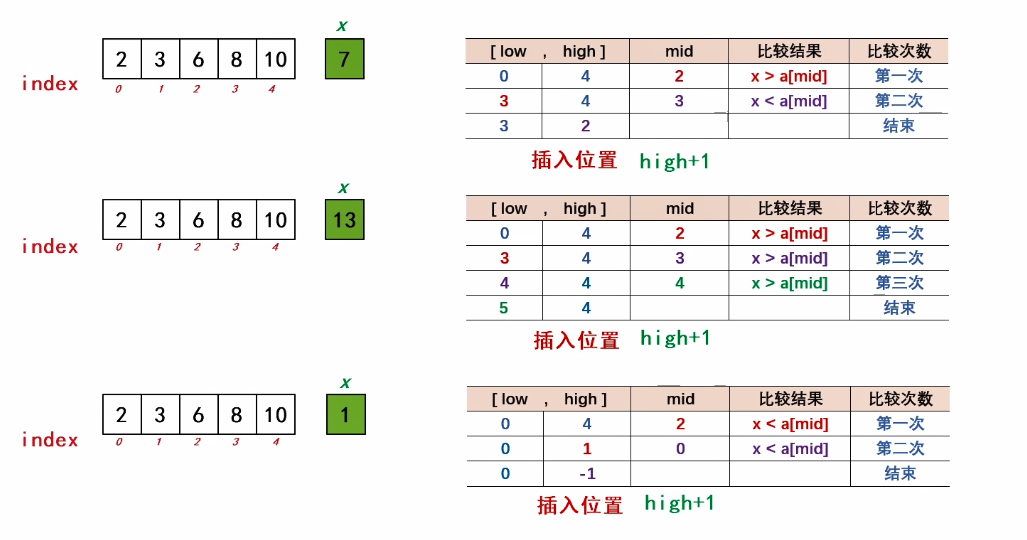
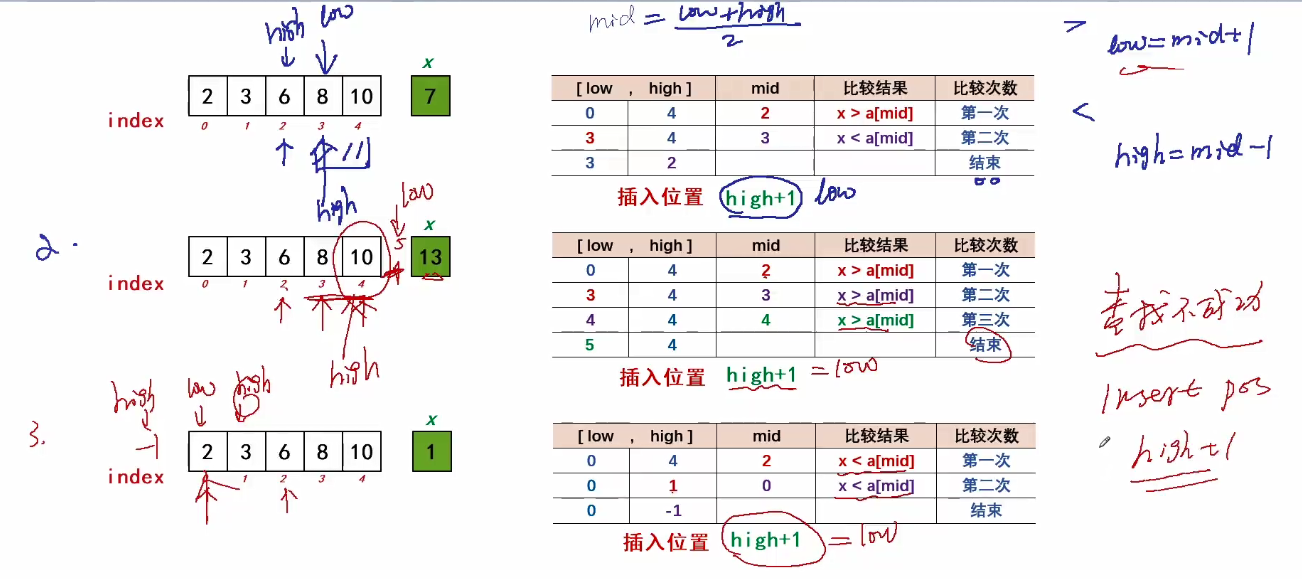

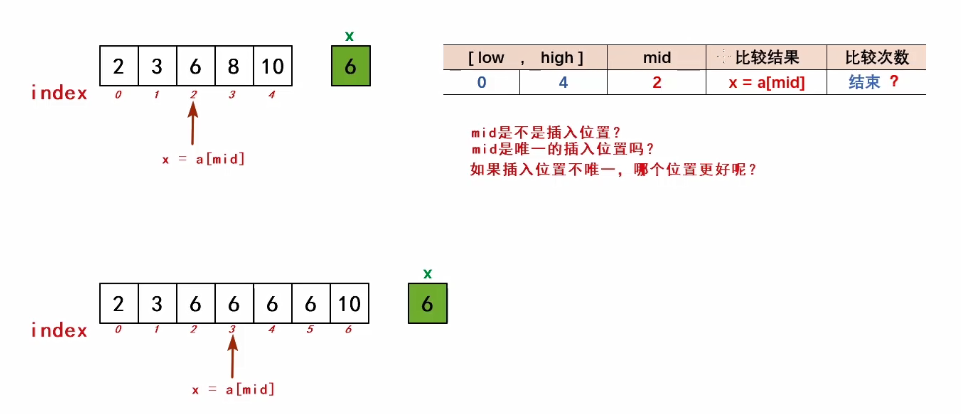
(2)查找成功
(原有序表中有待插入的元素)时,插入位置的确定
靠后的插入位置,更优化(后续挪动次数会少一些)
low = mid+1,when x == a[mid]
...
=> 查找不成功
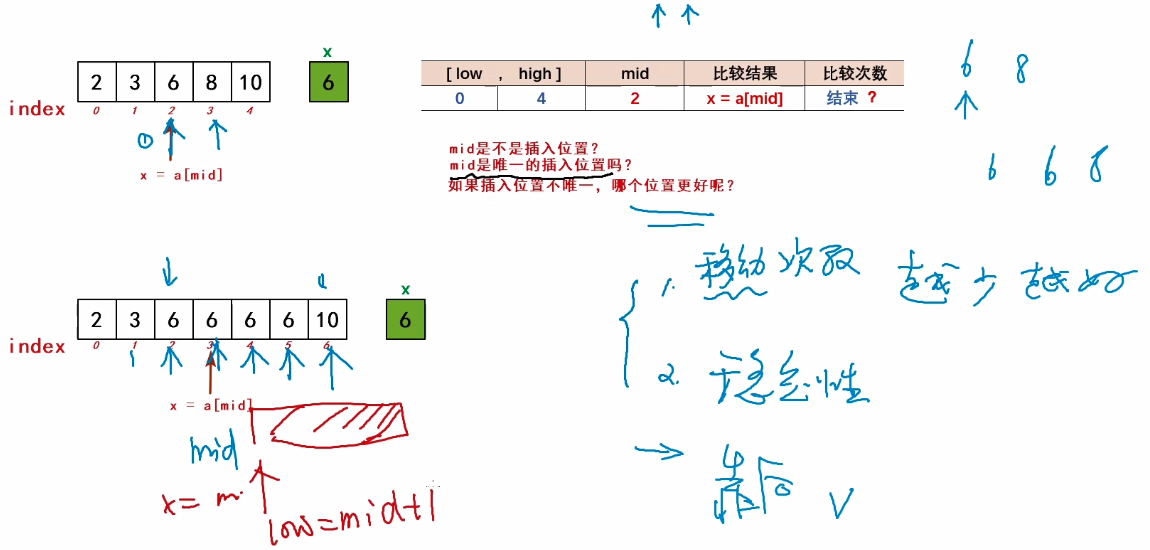

step 2:插入操作
(1)先挪元素
[last,---> Insertion Position] high+1
(2)插入操作
x->[Insertion Position]
x->a[high +1]
代码实现
#include <stdio.h>
#define N 5
/*
BinInsert:一次折半插入
@a:有序表,数组名
@n:有序表的元素个数
a[0] a[1] ... a[n-1]
@x:待插入元素
返回值:
无
*/
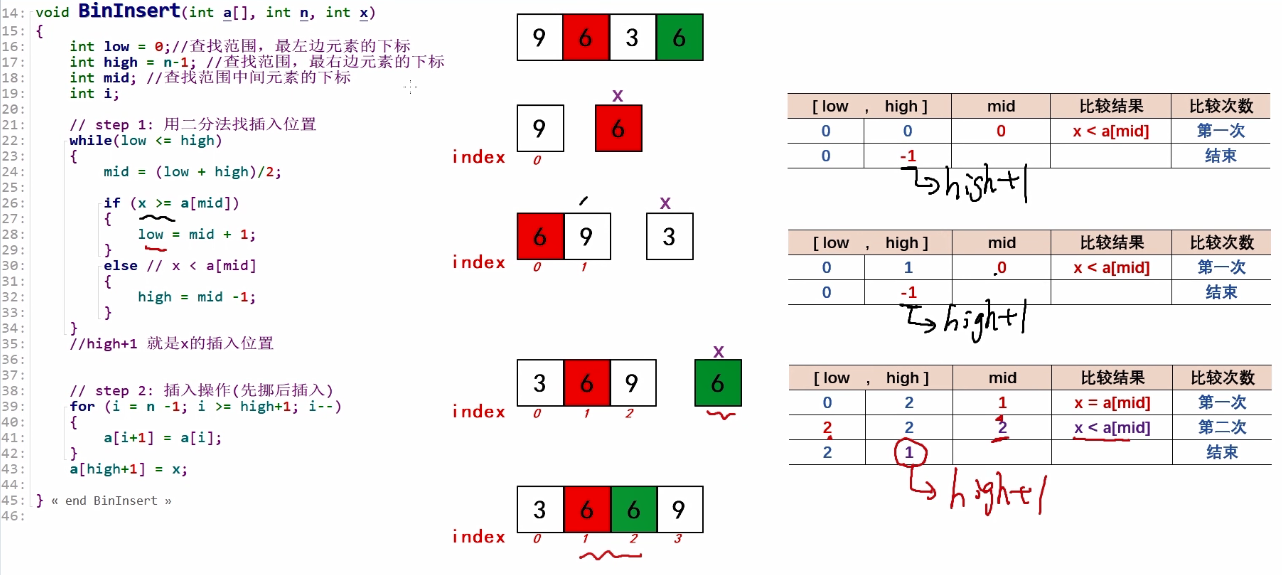
void BinInsert(int a[], int n,int x)
{
int i;
int low = 0;//查找范围,最左边元素的下标
int high = n-1;//查找范围,最右边元素的下标
int mid;//查找范围中间元素的下标
//step 1:用二分法找插入位置
while(low <= high)
{
mid = (low + high)/2;
if(x >= a[mid])
{
low = mid + 1;
}
else //x < a[mid]
{
high = mid - 1;
}
}
//high+1 就是x的插入位置
//step2: 插入操作(先挪后插入)
for(i = n - 1; i >= high+1; i--)
{
a[i+1] = a[i];
}
a[high+1] = x;
}
void insertSort(int a[] , int n)
{
int i,j;
for(i = 1; i < n; i++)
{
BinInsert(a,i,a[i]);
}
}
int main()
{
int a[N]={0};
int i;
for(i=0;i<N;i++)
{
scanf("%d",&a[i]);
}
insertSort(a,N);
for(i=0;i<N;i++)
{
printf("%d",a[i]);
}
printf("\n");
return 0;
}3.折半插入排序的性能分析
(1)时间复杂度
一次BinInsert的时间T=Ts +Tm
其中 Ts 为一次二分查找的时间
二分查找插入位置时,都是“查找不成功(查找最坏)”的情况
so,每次查找比较次数为:1og2N
Ts=t1*log2N
Tm为一次移动元素的时间 根据插入位置,每次插入移动元素的个数,分为: 最好情况:移动一个 最坏情况:移动n个 平均情况:移动(n/2)
所以,我们根据移动元素的情形,把折半插入排序的时间复杂度分为三种情况: 最好情况:
O(nlog2N)

最坏情况:
O( n2)

平均情况:
O( n2)
(2)空间复杂度
O(1)
4.折半插入排序稳定性分析
折半插入排序 是 稳定的。
5.总结
折半插入排序相比直接插入排序只优化了查找插入位置的比较次数,移动元素的次数并没有解决。所以: (1)当数据元素比较多(N值比较大)or (2)移动元素的代价 小于 关键字比较时
采用折半插入排序比较有优势。
四、希尔排序
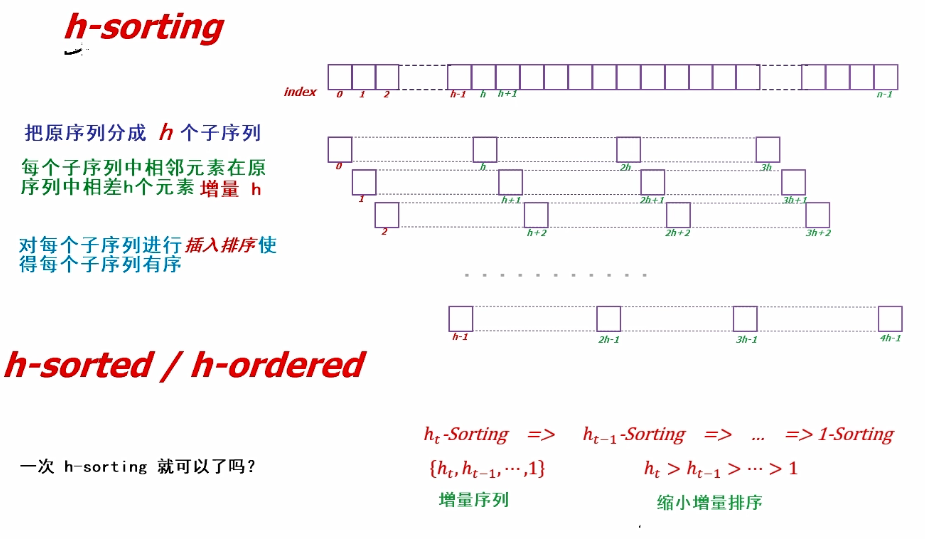
1.什么是希尔排序
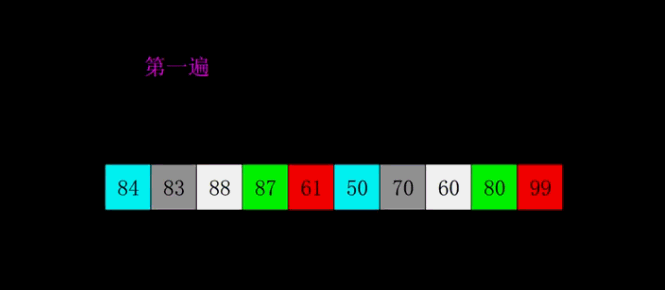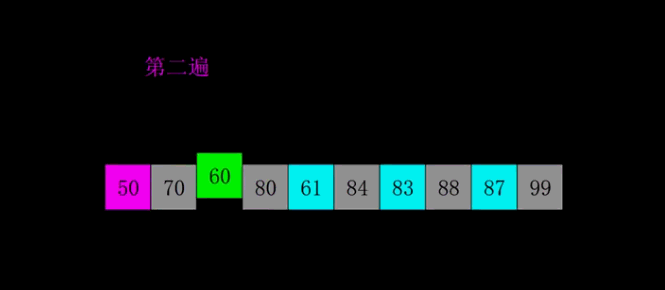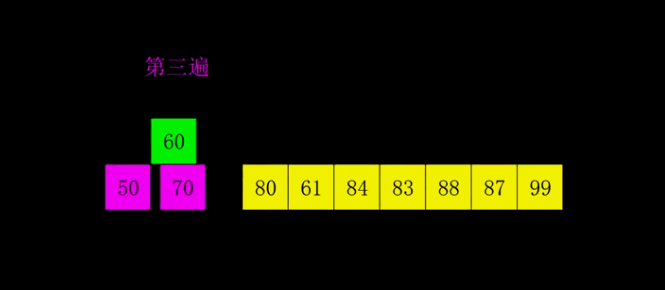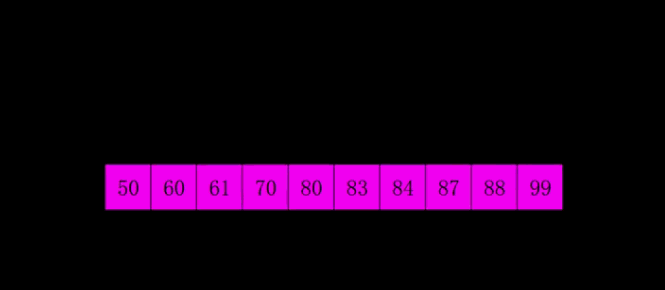
希尔排序,是由Donald shel1于1959年提出的一种排序算法。又称“缩小增量排序”,是插入排序的一种。 基本思想: (1)把待排序列,分成多个间隔为h的子序例,
然后对每个子序列进行直接插入排序;
重复(1)多次,每次间隔h不同(并且越来越小),
最后一次选取间隔h=1,完成排序。
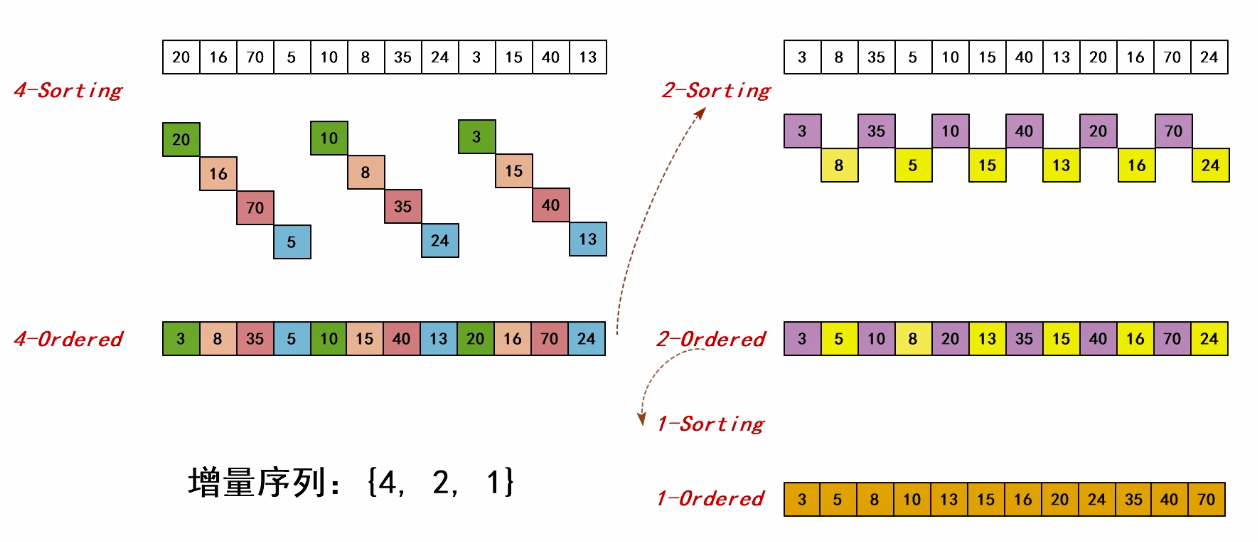
2.算法思路
h-sorting 增量h排序 / "间隔h排序"
h-sorted/h-ordered 增量h有序 / ”间隔h有序"
代码实现
#include<stdio.h>
#define N 5
/*
h_sorting:一次增量h排序
@a:进行增量h排序的原始序列,数组名
@n:原有序表的元素个数,
a[0] a[1] ,..., a[n-1]
@h:增量h/间隔h
返回值:
无返回
*/
void h_sorting(int a[], int n, int h)
{
int i,j;
int x;
for(i = h; i < n; i++)
{
x = a[i];
for(j = i - h; j >= 0 && a[j] > x; j = j-h)
{
a[j+h] = a[j];
}
a[j+h] = x;
}
}
//对数组a,进行一个shell排序
void shell_sort(int a[], int n)
{
int i;
//增量序列
int h[] = {8,4,2,1};
for(i = 0; i < 4; i++)
{
h_sorting(a, n, h[i]);
}
}
int main()
{
int i;
int a[N];
for(i = 0; i < N; i++)
{
scanf("%d",&a[i]);
}
shell_sort(a, N);
for(i = 0; i < N; i++)
{
printf("%d\t",a[i]);
}
return 0;
}3.希尔插入排序的性能分析
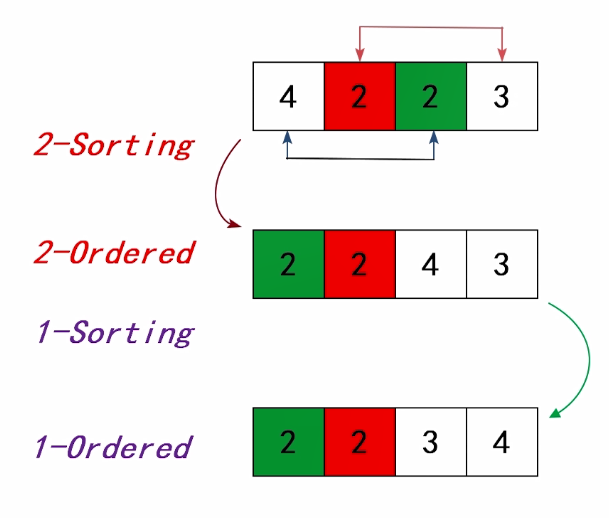
关于希尔排序的几个基本认知: (1)ht-Orderd序列,在后面的hi-sorting后,将仍然保持它的排序性;【定理】 (2)在h-sorting时,采用插入排序被证实比其他排序方法效率更高; (3)不同的增量序列,对希尔排序的性能影响比较大。
(1)时间复杂度
一般认为,希尔排序的时间复杂度为: 平均/最坏情况下 最好的情况下(本身就是有序的) O(nr),1<r<2 O(nlog2n)

(2)空间复杂度
O(1)
4.希尔排序稳定性分析
希尔排序是一种 不稳定 的排序方法。
5.总结
适用场景
Shell排序虽然快,但是毕竟是插入排序,其数量级并没有后起之秀--快速排序O(n㏒n)快。在大量数据面前,Shell排序不是一个好的算法。但是,中小型规模的数据完全可以使用它。
五、冒泡排序
1.什么是冒泡排序
冒泡排序(BubbleSort),是一种简单的排序算法。
它“从头到尾”重复遍历要排序的数列,一次比较两个元素,如果他们的顺序是错的,就把他们交换过来。
遍历数列的工作要重复进行,直到没有元素需要交换,此时排序完成。
“相邻元素两两比较,如果顺序是错的,就交换他们"
2.算法思路
(1)比较第一个和第二个元素。如果第一个比第二个大,就交换他们两个
(2)比较第二个和第三个元素。如果第二个比第三个大,就交换他们两个
……
(n)比较第n-1个和第n个元素。如果第n-1个比第n个大,就交换他们两个
上面过程实际上是对每一对相邻元素作同样的比较交换工作,
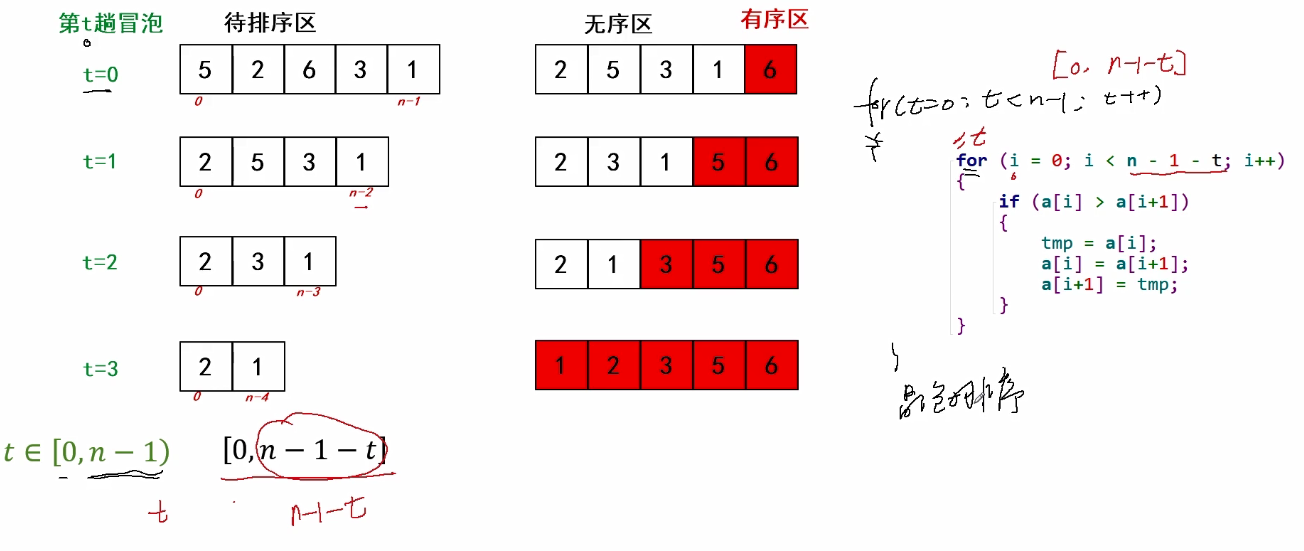
从第一对到最后一对,这一趟做完后,最大的元素会在最后的位置上。
“一趟冒泡":把一个最大的元素归位。
上面冒泡"过程,重复N-1(最多N-1)趟,所有元素都会归位。
“N-1趟冒泡":排序完成。

代码实现
#include<stdio.h>
#define N 5
//冒泡排序
void bubble_sort(int a[], int n)
{
int i;
int t = 0; //第t趟冒泡 [0, N-1]
int temp;
for(t = 0; t < n - 1; t++)
{
//[0, n-1-t] 第t趟冒泡,待排序区的下标
//一趟冒泡
for(i = 0; i < n-1-t; i++)
{
if(a[i] > a[i+1])
{
temp = a[i];
a[i] = a[i+1];
a[i+1] = temp;
}
}
}
}
int main()
{
int i;
int a[N];
for(i = 0; i < N; i++)
{
scanf("%d",&a[i]);
}
bubble_sort(a, N);
for(i = 0; i < N; i++)
{
printf("%d\t",a[i]);
}
return 0;
}代码改进
#include<stdio.h>
#define N 5
//冒泡排序
void bubble_sort(int a[], int n)
{
int i;
int t = 0; //第t趟冒泡 [0, N-1]
int temp;
int exchange = 0;//标记,是否有元素进行交换
//1 表示有元素进行交换
//0 表示没有元素进行交换
for(t = 0; t < n - 1; t++)
{
//[0, n-1-t] 第t趟冒泡,待排序区的下标
//一趟冒泡
for(i = 0; i < n-1-t; i++)
{
if(a[i] > a[i+1])
{
temp = a[i];
a[i] = a[i+1];
a[i+1] = temp;
exchange = 1;
}
}
if(exchange == 0)//刚刚那趟冒泡过程,没有发生元素交换,
{
break;
}
}
}
int main()
{
int i;
int a[N];
for(i = 0; i < N; i++)
{
scanf("%d",&a[i]);
}
bubble_sort(a, N);
for(i = 0; i < N; i++)
{
printf("%d\t",a[i]);
}
return 0;
}另外的版本
/*优化过的正宗版本的冒泡排序*/
/*用flag模拟布尔类型,如果遍历一遍后没有元素位置的交换就不再进行再次遍历排序*/
#include <stdio.h>
void BubbleSort(int k[], int n)
{
int i, j, temp, count1=0, count2=0, flag;
flag = 1;
for( i=0; i < n-1 && flag; i++ )
{
for( j=n-1; j > i; j-- )
{
count1++;
flag = 0;
if( k[j-1] > k[j] )
{
count2++;
temp = k[j-1];
k[j-1] = k[j];
k[j] = temp;
flag = 1;
}
}
}
printf("总共进行了%d次比较,进行了%d次移动!", count1, count2);
}
int main()
{
int i, a[10] = {5, 2, 6, 0, 3, 9, 1, 7, 4, 8};
BubbleSort(a, 10);
printf("排序后的结果是:");
for( i=0; i < 10; i++ )
{
printf("%d", a[i]);
}
printf("\n\n");
return 0;
}3.冒泡排序的性能分析
(1)时间复杂度
a.最好情况

b.最坏情况
c.平均情况

(2)空间复杂度
O(1)
4.冒泡排序稳定性分析
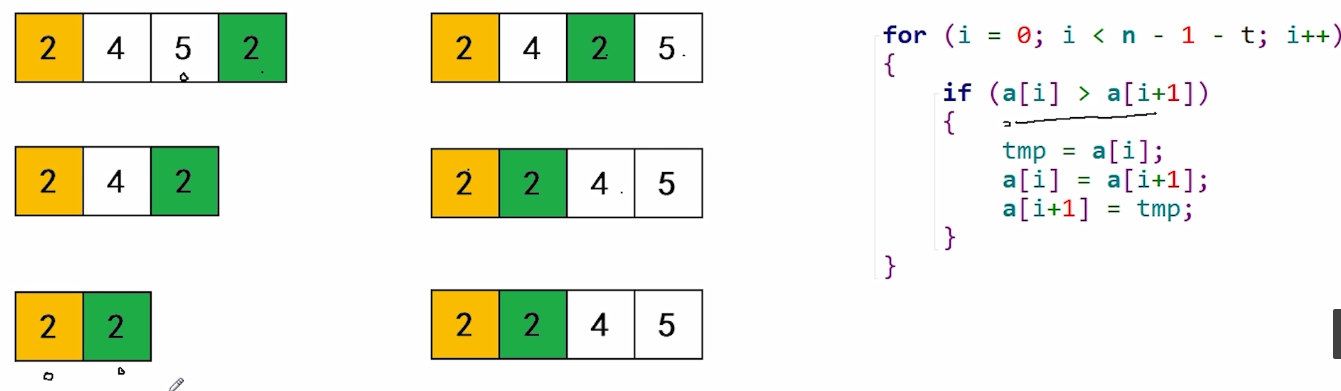
冒泡排序是一种 稳定的 排序方法。
5.总结
简言之,冒泡排序除开它迷人的名字和导致了某些有趣的理论问题这一事实之外,似乎没有什么值得推荐的。---Knuth《计算机程序设计艺术》
(1)什么时候最快
当输入的数据已经是正序时(都已经是正序了,我还要你冒泡排序有何用啊)。
(2) 什么时候最慢
当输入的数据是反序时(写一个 for 循环反序输出数据不就行了,干嘛要用你冒泡排序呢,我是闲的吗)。
(3)适用场景
冒泡排序思路简单,代码也简单,特别适合小数据的排序。但是,由于算法复杂度较高,在数据量大的时候不适合使用。
六、快速排序
1.什么是快速排序
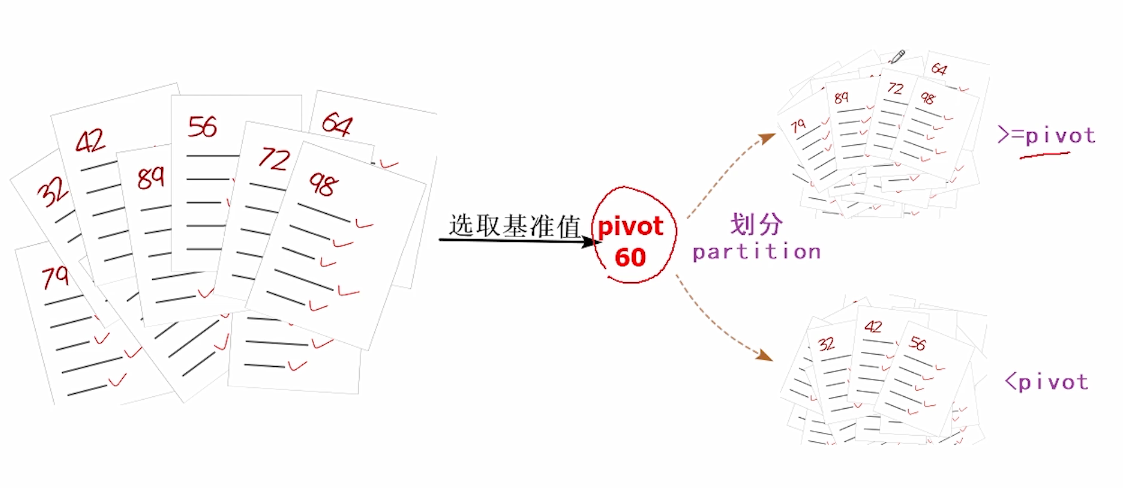
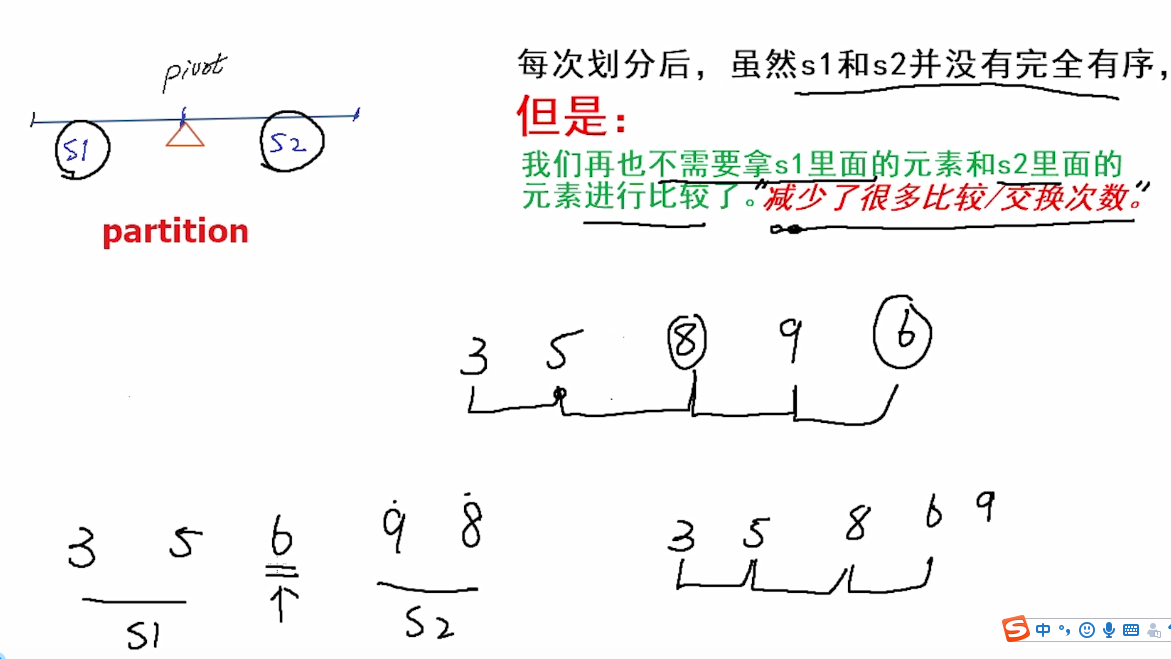
快速排序(英语:QuickSort)是一种高效的排序算法,最早由英国计算机科学家Tony Hoare于1959年发明。 快速排序不断重复的一个操作是:选取一个基准值(pivot),然后把原序列划分(partition)为两部分,一部分小于基准值,另外一部分大于等于基准值,所以快速排序又称划分交换排序(partition-exchange sort)。

2.算法思路
快速排序采用分治算法(divide-and-conquer),它是这样工作的: (1)从待排序的数列中选择一个基准元素(pivot),然后(2)把剩余元素划分(“分割”)为两个子数列: 小于基准元素值的子序列S1和 大于等于基准元素值的子序列s2 (3)子序列S1和s2按同样的方法递归执行(1)和(2),直到序列中的元素个数为0或1。
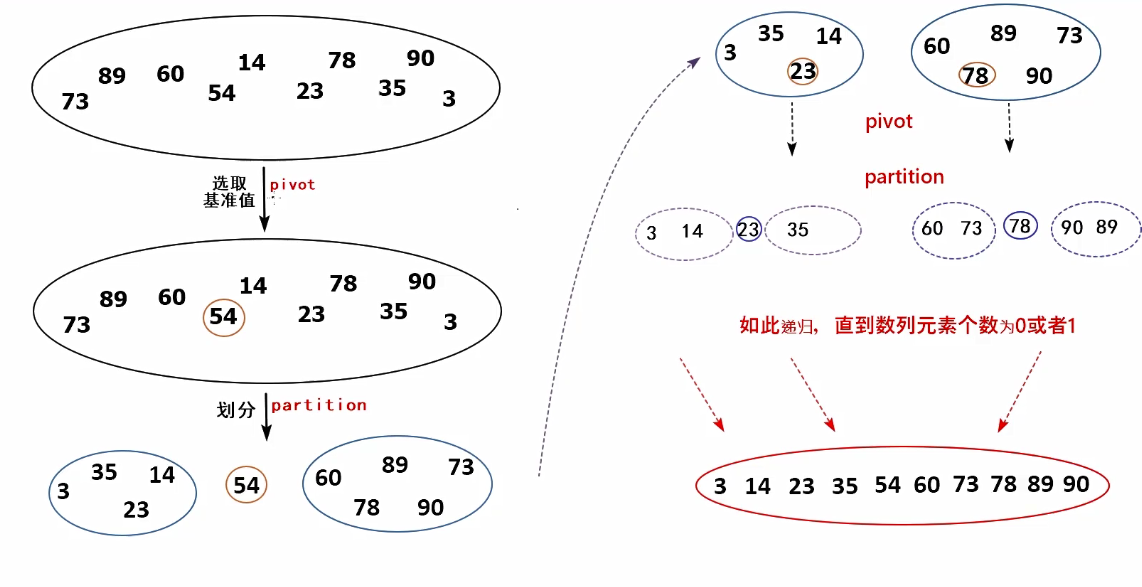
具体的算法步骤:Qsort(A[ ],left,right)
关键:把序列分割成两部分:“小”基准值“大”
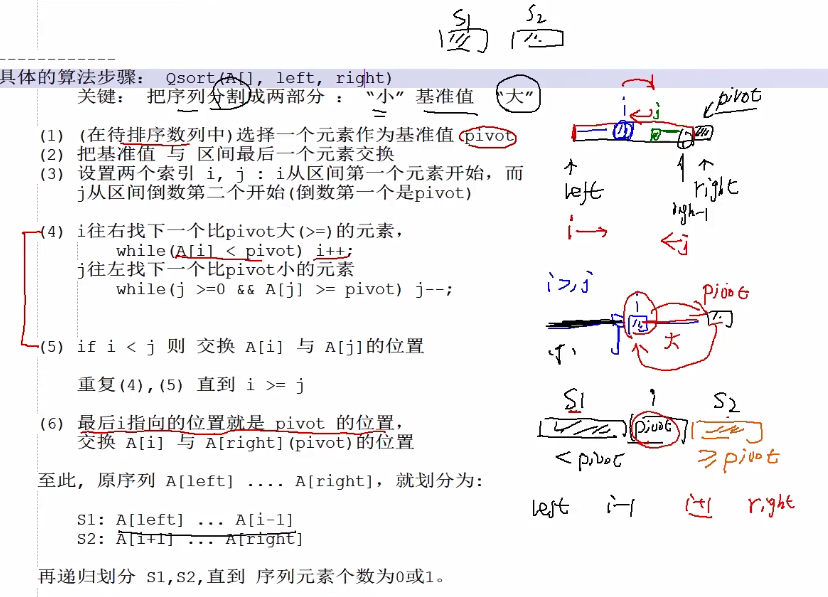
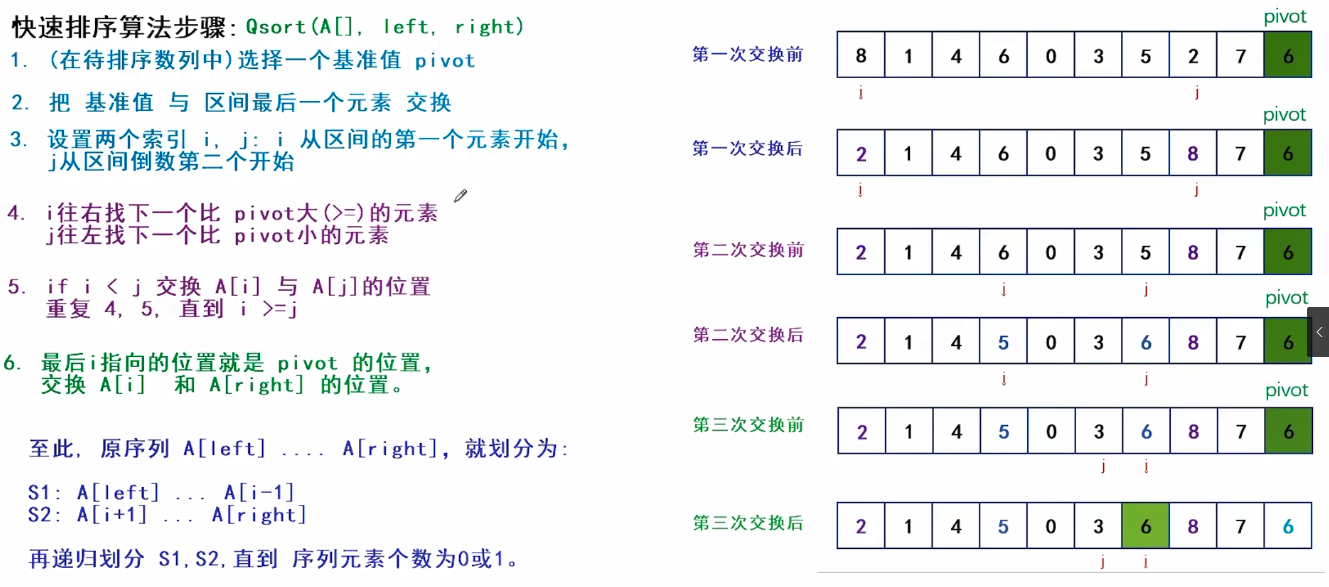
(1)(在待排序数列中)选择一个元素作为基准值pivot
(2)把基准值与区间最后一个元素交换
(3)设置两个索i,j : i从区间第一个元素开始,而 j 从区间倒数第二个开始(倒数第一个是pivot)
(4)i往右找下一个比pivot大(>=)的元素,
while(A[i]<pivot)i++;
j往左找下一个比pivot小的元素
while(j>=0&&A[j]>=pivot)j--;
(5)ifi<j则交换A[i]与A[j]的位置
重复(4),(5)直到i>=j
代码实现
#include<stdio.h>
#define N 5
typedef int ElemType;
void swap(ElemType *p,ElemType *s)
{
ElemType t;
t = *p;
*p = *s;
*s = t;
}
/*
QSort:把数列A[1eft]...A[right]进行快速的排序
@A:数组名
@left:待排序数列最左边元素的下标
@right:待排序数列最右边元素的下标
返回值:
无。
*/
void QSort(ElemType A[], int left, int right)
{
if(left >= right)
{
return ;
}
ElemType pivot = A[right];
//1.选取一个基准值
//2.把基准值元素与 最后一个元素交换
//3.设置两个索引 i,j;
// i从第一个元素开始往右遍历
// j从倒数第二个元素开始往左遍历
int i = left;
int j = right - 1;
for(; ; )
{
//4.”两头点蜡“
//i从左->右,找下一个比pivot大(>=)的元素
while(A[i] < pivot) i++;
//j从右->左,找下一个比pivot小的元素
while(j >= 0 && A[j] >= pivot) j--;
if(i < j)
{
//交换:把大的元素放在序列的右边
// 把小的元素放在序列的左边
swap(&A[i], &A[j]);
}
else //i >= j
{
break;
}
}
//6.i 指向的位置就是pivot的位置
swap(&A[i], &A[right]);
//S1: A[left] ... A[i-1]
QSort(A, left, i-1);
//S2:A[i+1] ... A[right]
QSort(A, i+1, right);
}
void QuickSort(ElemType A[], int n)
{
QSort(A, 0, n-1);
}
int main()
{
int i;
int a[N];
for(i = 0; i < N; i++)
{
scanf("%d",&a[i]);
}
QuickSort(a, N);
for(i = 0; i < N; i++)
{
printf("%d\t",a[i]);
}
return 0;
}3.三数中值分割法
快排 pivot 选择策略
1.每次固定选择序列中的第一个or最后一个元素作为pivo如果输入序列是随机的,那么这种策略是可以接受的但是如果输入是预排序的或反序的,那么这种策略下的分割是非常糟糕的,因为所有的元素不是被划入s1就是被划入S2
预排序的输入(或具有一大预排序数据的输入)是相当常见的,因此这种策略绝对是糟糕的主意
2.般来说这种策略非常安全,除非随机数生成器有问题,因为随机的 pivot 不可能总是产生劣质的要割方面,随机数的生成一般是昂贵的,所以这种策略根本减少了算法其余的平均运行时间
3.三数中值分割法( Median-of- Three Partitioning) pivot的最好的选择是数列的中值
不幸的是,这很难算出。所以中值只能估计,中值的估计量可以通过随机选取三个元素,并用它们的中值作为 pivot而得到事实上,随机性并没有多大帮助,因此一般的做法是使用左端、右端、和中心位置上三个元素的中值作为pivot


代码实现
#include<stdio.h>
#define N 5
typedef int ElemType;
void swap(ElemType *p,ElemType *s)
{
ElemType t;
t = *p;
*p = *s;
*s = t;
}
/*
QSort:把数列A[1eft]...A[right]进行快速的排序
@A:数组名
@left:待排序数列最左边元素的下标
@right:待排序数列最右边元素的下标
返回值:
无。
*/
void QSort(ElemType A[], int left, int right)
{
if(left >= right)
{
return ;
}
ElemType pivot; //= A[right];
//1.选取一个基准值
//2.把基准值元素与 最后一个元素交换
// 采用“三数分割法”
int center = (left + right)/2;
if(A[left] > A[center])
{
swap(&A[left], &A[center]);
}
if(A[left] > A[right])
{
swap(&A[left], &A[right]);
}
if(A[center] > A[right])
{
swap(&A[center], &A[right]);
}
// A[left] <= A[center] <= A[right]
pivot = A[center];
swap(&A[center], &A[right-1]); // left....right-1
// pivot:A[right - 1]
//3.设置两个索引 i,j;
// i从第一个元素开始往右遍历
// j从倒数第二个元素开始往左遍历
int i = left;
int j = right - 1;
for(; i < j ; )
{
//4.”两头点蜡“
//i从左->右,找下一个比pivot大(>=)的元素
while(A[++i] < pivot);
//j从右->左,找下一个比pivot小的元素
while(A[--j] > pivot);
if(i < j)
{
//交换:把大的元素放在序列的右边
// 把小的元素放在序列的左边
swap(&A[i], &A[j]);
}
else //i >= j
{
break;
}
}
//6.i 指向的位置就是pivot的位置
swap(&A[i], &A[right-1]);
//S1: A[left] ... A[i-1]
QSort(A, left, i-1);
//S2:A[i+1] ... A[right]
QSort(A, i+1, right);
}
void QuickSort(ElemType A[], int n)
{
QSort(A, 0, n-1);
}
int main()
{
int i;
int a[N];
for(i = 0; i < N; i++)
{
scanf("%d",&a[i]);
}
QuickSort(a, N);
for(i = 0; i < N; i++)
{
printf("%d\t",a[i]);
}
return 0;
}4.快速排序的性能分析
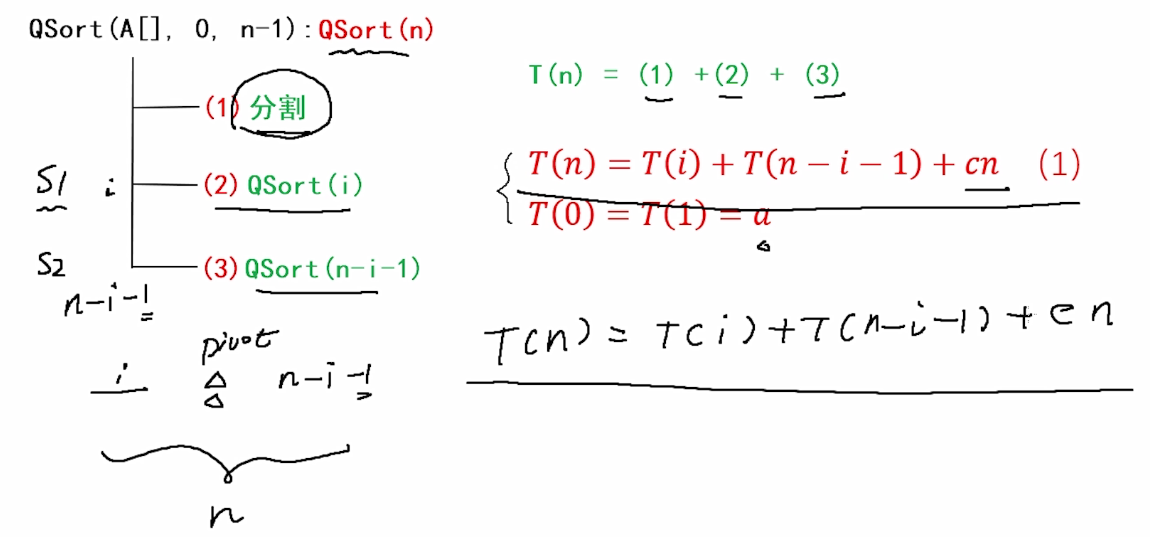
(1)时间复杂度
a.最坏情况

b.最好情况
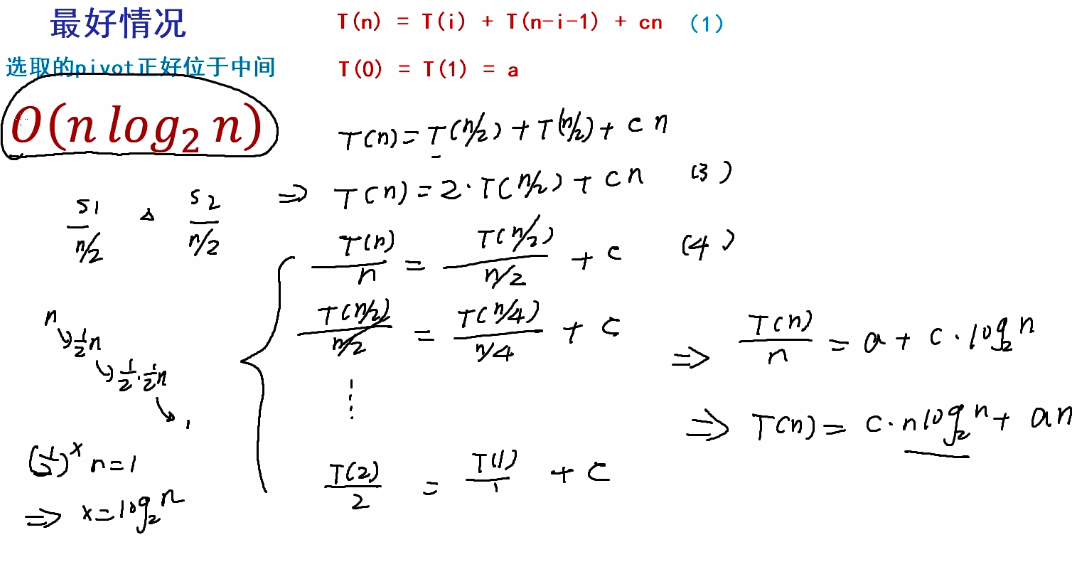
c.平均情况


(2)空间复杂度
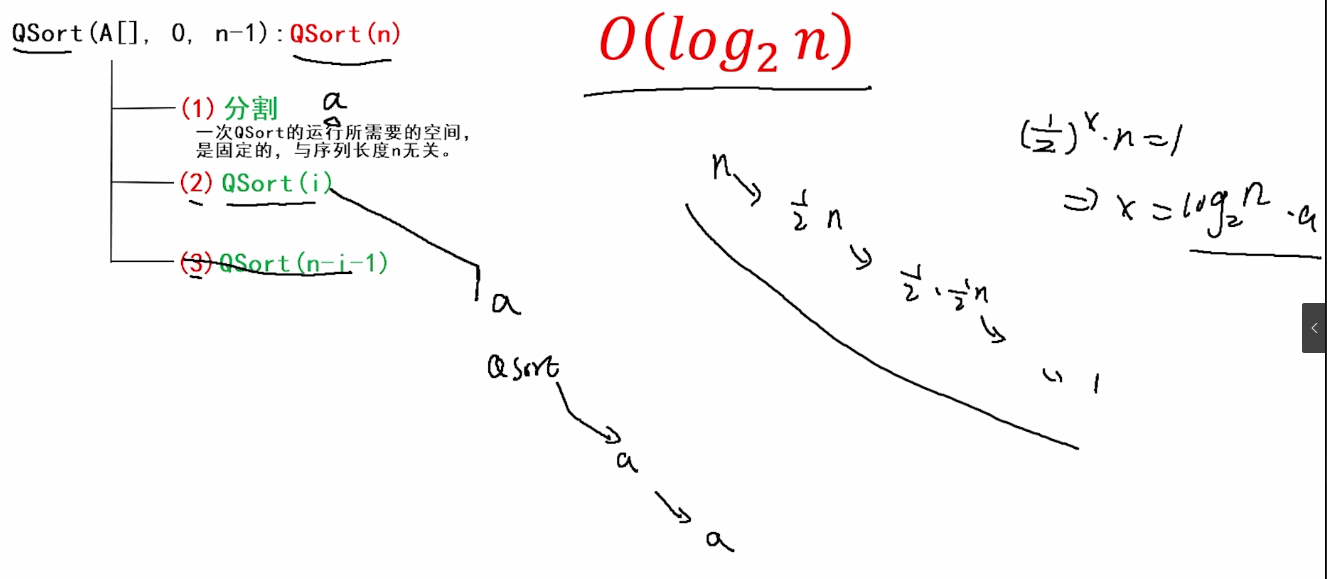
5.快速排序稳定性分析
快速排序是 不稳定 的。
6.总结
适用场景
快速排序在大多数情况下都是适用的,尤其在数据量大的时候性能优越性更加明显。但是在必要的时候,需要考虑下优化以提高其在最坏情况下的性能。
关于快速排序对于很小的数组(<=20),快速排序不如插入排序好不仅如此;因为快速排序是递归,所以这样的情形还经常发生。 通常的解决方法是对于小的数组不递归地使用快速排序,而代之以如插入排序这样对小数组有效的排序算法。 所以一般在实现快速排序算法(如:c/c++标准库中)时,定义一个递归的截止范围( cutoff range),当序列元素个数小于这个范围时,使用直接插入排序。
使用方法
#define cutoff 10 //数组长度小于10用插入排序,大于10使用快速排序
/*
对于小的数组不递归地使用快速排序,而代之以如插入排序这样对小数组有效的排序算法。
*/
void QSort(ElemType A[], int left, int right)
{
if(right - left < cutoff)
{
insertsort(A+left, right-left+1);
}
else
{
ElemType pivot; //= A[right];
//1.选取一个基准值
//2.把基准值元素与 最后一个元素交换
// 采用“三数分割法”
int center = (left + right)/2;
if(A[left] > A[center])
{
swap(&A[left], &A[center]);
}
if(A[left] > A[right])
{
swap(&A[left], &A[right]);
}
if(A[center] > A[right])
{
swap(&A[center], &A[right]);
}
// A[left] <= A[center] <= A[right]
pivot = A[center];
swap(&A[center], &A[right-1]); // left....right-1
// pivot:A[right - 1]
//3.设置两个索引 i,j;
// i从第一个元素开始往右遍历
// j从倒数第二个元素开始往左遍历
int i = left;
int j = right - 1;
for(; i < j ; )
{
//4.”两头点蜡“
//i从左->右,找下一个比pivot大(>=)的元素
while(A[++i] < pivot);
//j从右->左,找下一个比pivot小的元素
while(A[--j] > pivot);
if(i < j)
{
//交换:把大的元素放在序列的右边
// 把小的元素放在序列的左边
swap(&A[i], &A[j]);
}
else //i >= j
{
break;
}
}
//6.i 指向的位置就是pivot的位置
swap(&A[i], &A[right-1]);
//S1: A[left] ... A[i-1]
QSort(A, left, i-1);
//S2:A[i+1] ... A[right]
QSort(A, i+1, right);
}
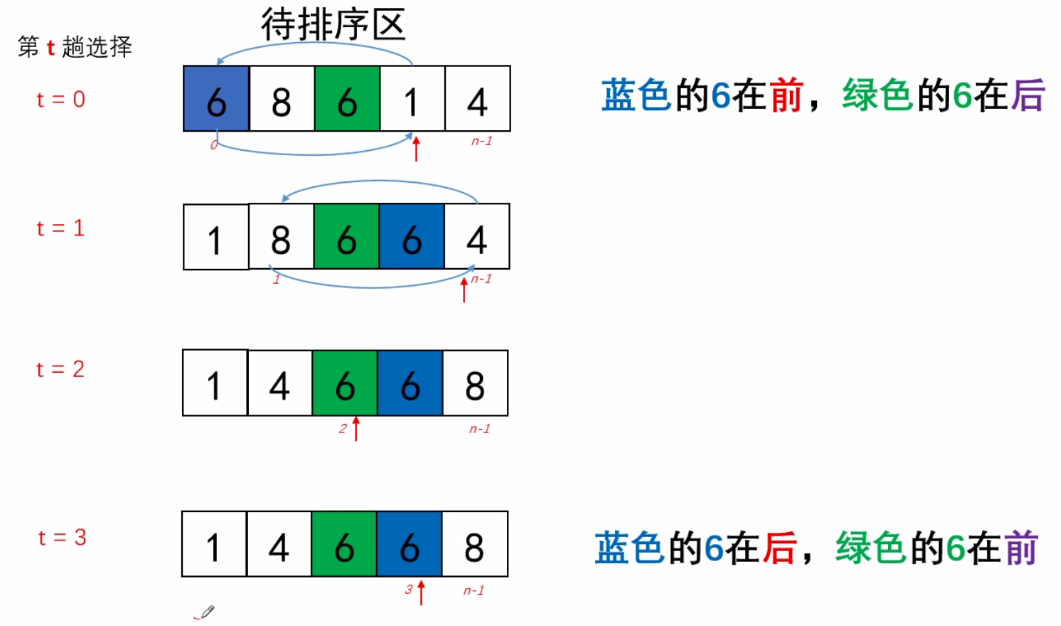
}七.选择排序
1.什么是选择排序
选择排序( Selection Sort)是一种简单直观的排序算法.
它的工作原理如下:
在未排序序列中( unsorted list,无序区)中找到最小(大)元素,和序列中的第一个元素交换位置;(这个操作会使最小元素归位)
然后,再从剩余的未排序元素中继续寻找最小(大)元素,重复上面的操作。
直到所有元素归位,排序完成
基本思想:
选择+交换
选择排序又分为:
直接选择排序(简单选择排序)
堆排序
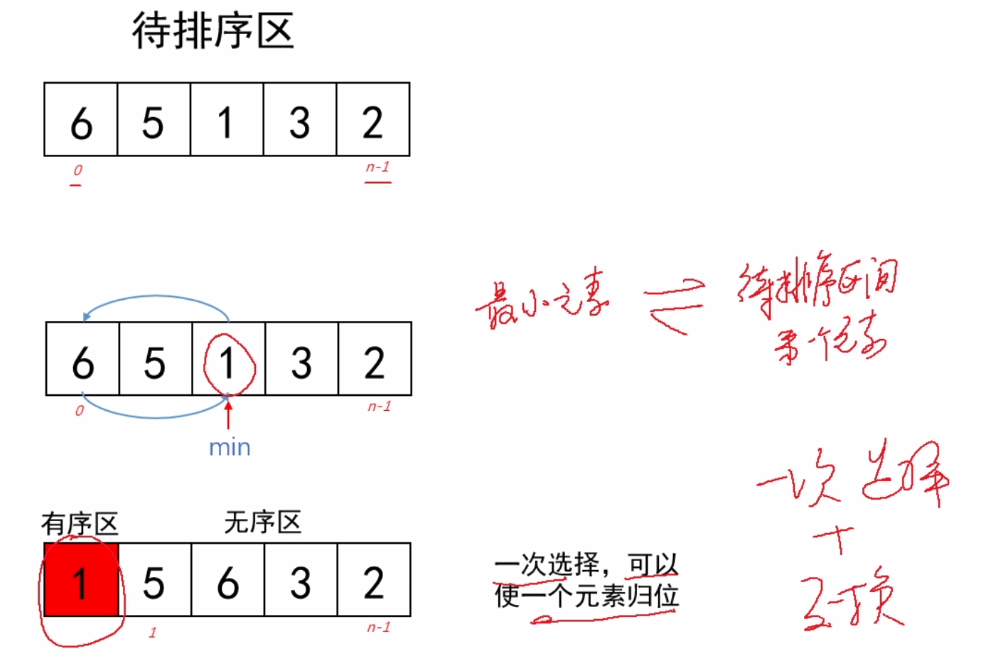
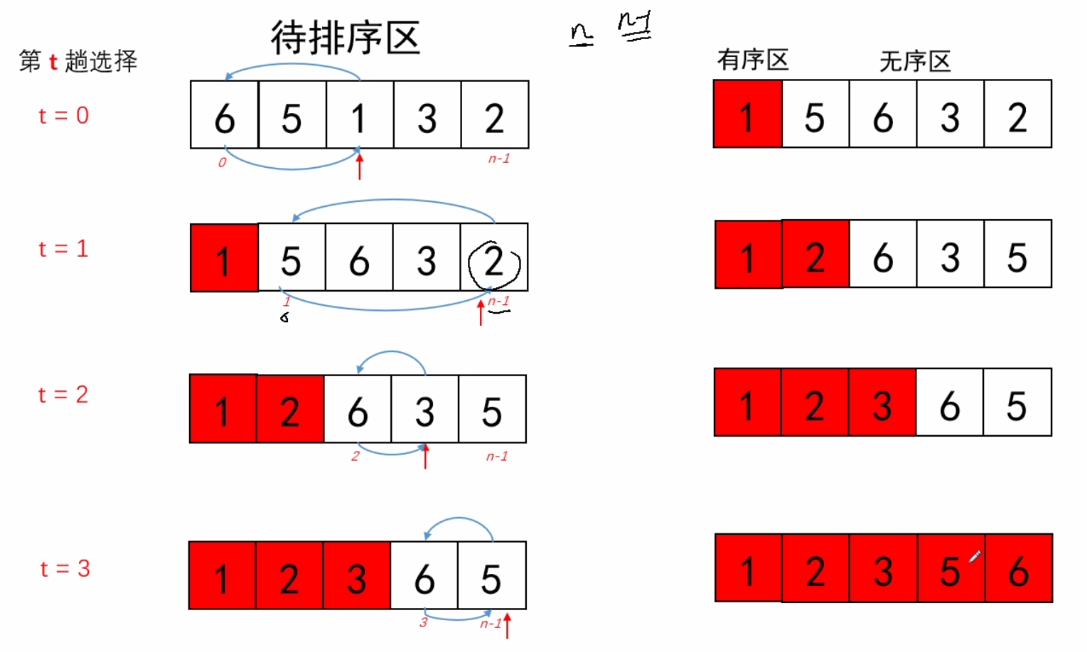
2.算法思路

(1)从待排序数列(无序区)中,选择一个关键字最小的元素;
(2)如果最小元素不是待排序数列的第一个元素,则交换他们;“一次选择交换”;
(3)从余下的N-1个元素中,选择最小的,重复(1)(2)步骤,直到排序完成。
整个序列:
经过N-1次的选择交换,排序完成
代码实现
#include <stdio.h>
#define N 5
void swap(int *p,int *s)
{
int t;
t = *p;
*p = *s;
*s = t;
}
/*
selection sort:直接选择排序
@a:待排序数组名
@n:待排序元素个数
返回值:
无
*/
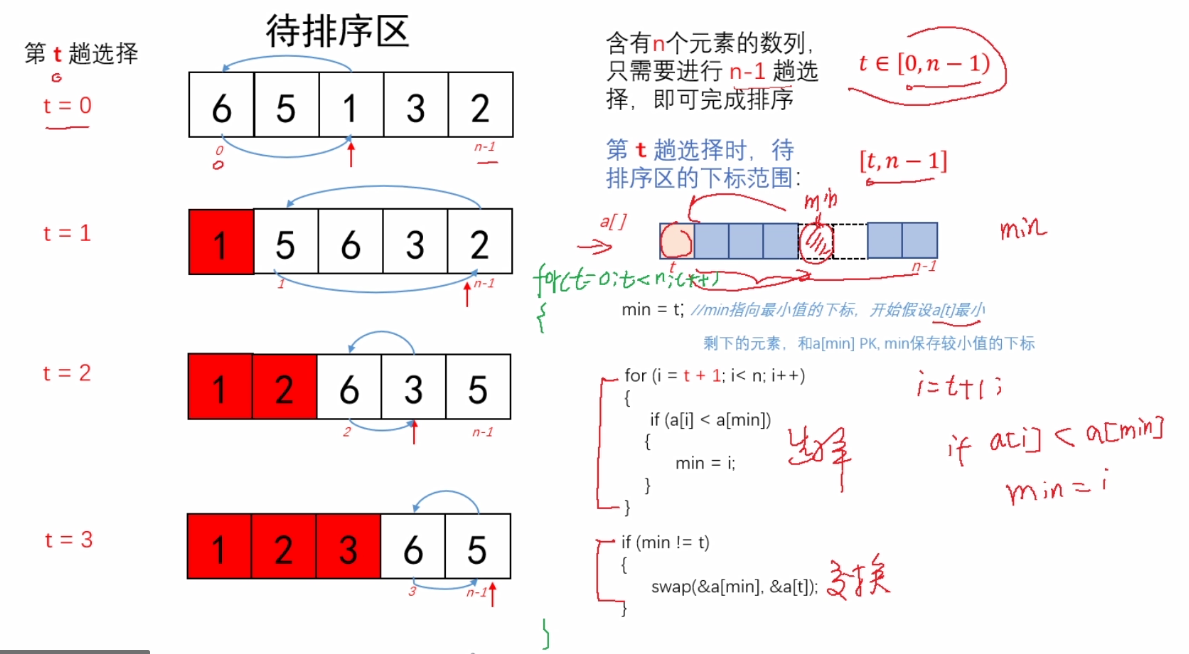
void selection_sort(int a[], int n)
{
int i;
int t;//选择的次数t [0,n-1]
int min;//指向每次选择区域最小元素
//第t趟选择, 选择区域下标[t, n-1]
for(t = 0; t < n-1; t++)
{
min = t;
for(i = t+1; i < n; i++)
{
if(a[i] < a[min])
{
min = i;
}
}
if(t != min)
{
swap(&a[t], &a[min]);
}
}
}
int main()
{
int i;
int a[N];
for(i = 0; i < N; i++)
{
scanf("%d",&a[i]);
}
selection_sort(a, N);
for(i = 0; i < N; i++)
{
printf("%d\t",a[i]);
}
return 0;
}3.选择排序的性能分析
(1)时间复杂度
比较次数o(n2)
交换次数 0次 最好情况
n-1次 最坏情况
0<,<n-1 平均情况
然而,无论元素的初始排列如何,所需进行的关键字比较次数相同均为:n(n-1)/2
选择排序时间复杂度(最好、最坏、平均)为:O(n2)
(2)空间复杂度
O(1)
4.选择排序稳定性分析
选择排序是一种 不稳定 的排序方法
5.总结
原地操作几乎是选择排序的唯一优点,当空间复杂度要求较高时,可以考虑选择排序;实际适用的场合非常罕见
适用场景
选择排序实现也比较简单,并且由于在各种情况下复杂度波动小,因此一般是优于冒泡排序的。在所有的完全交换排序中,选择排序也是比较不错的一种算法。但是,由于固有的O(n2)复杂度,选择排序在海量数据面前显得力不从心。因此,它适用于简单数据排序。
八.堆排序
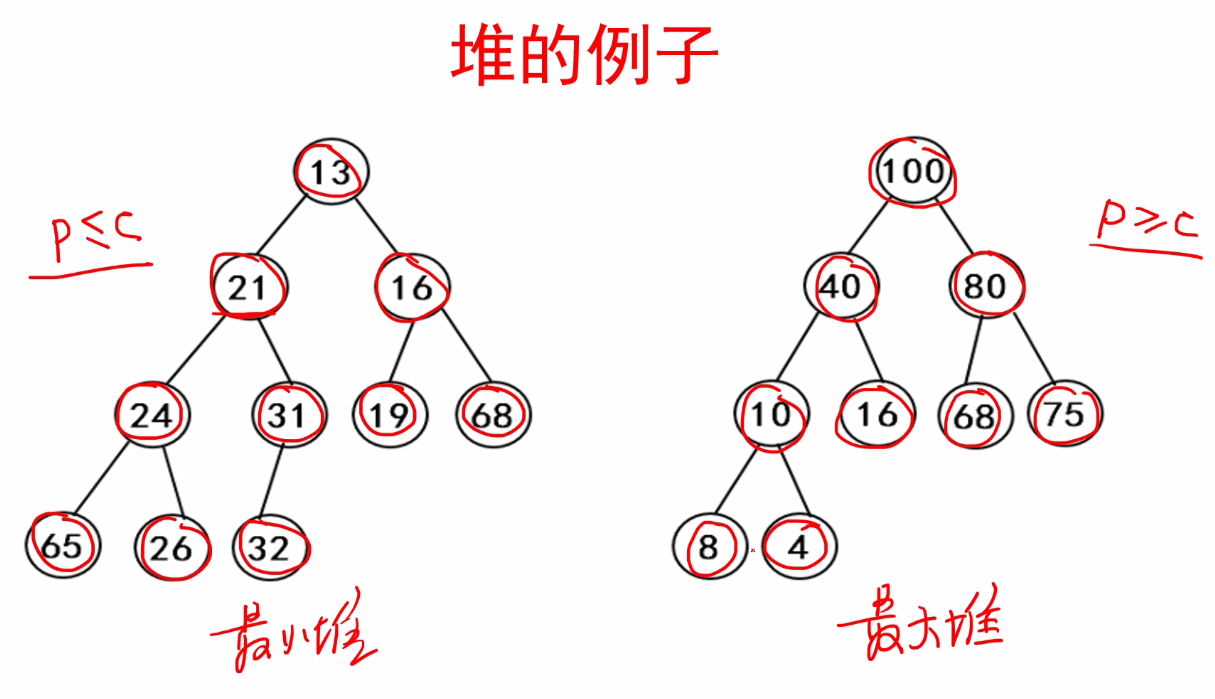
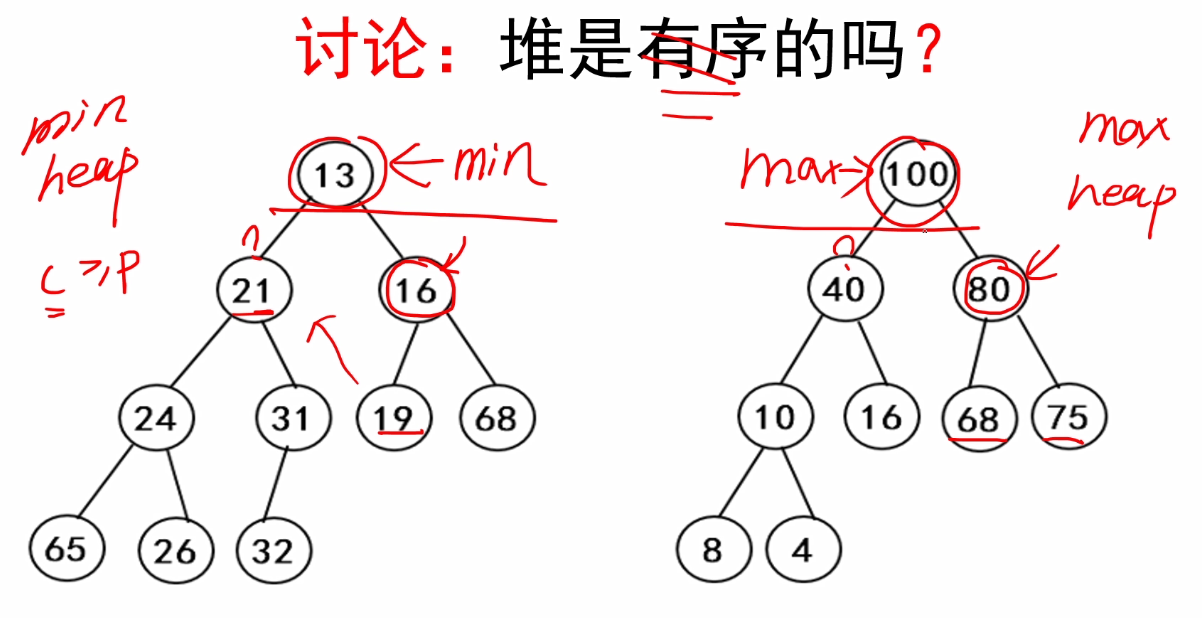
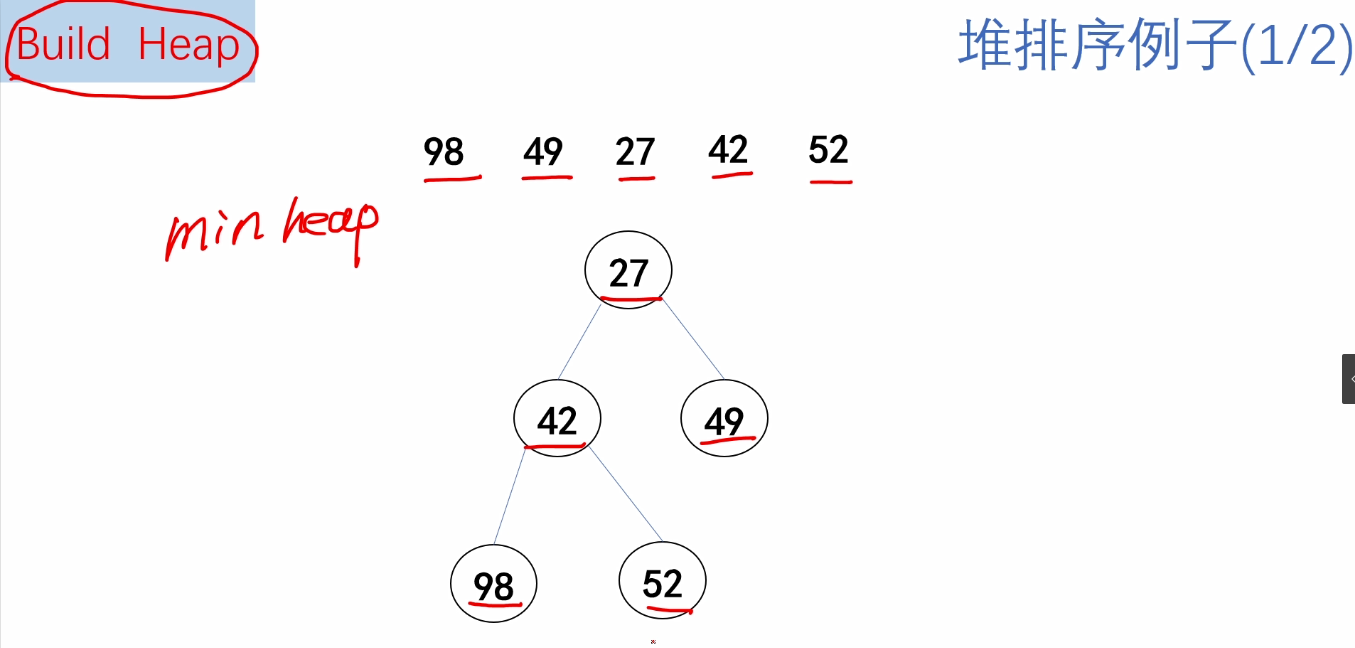
1.什么是堆排序




2.算法思路



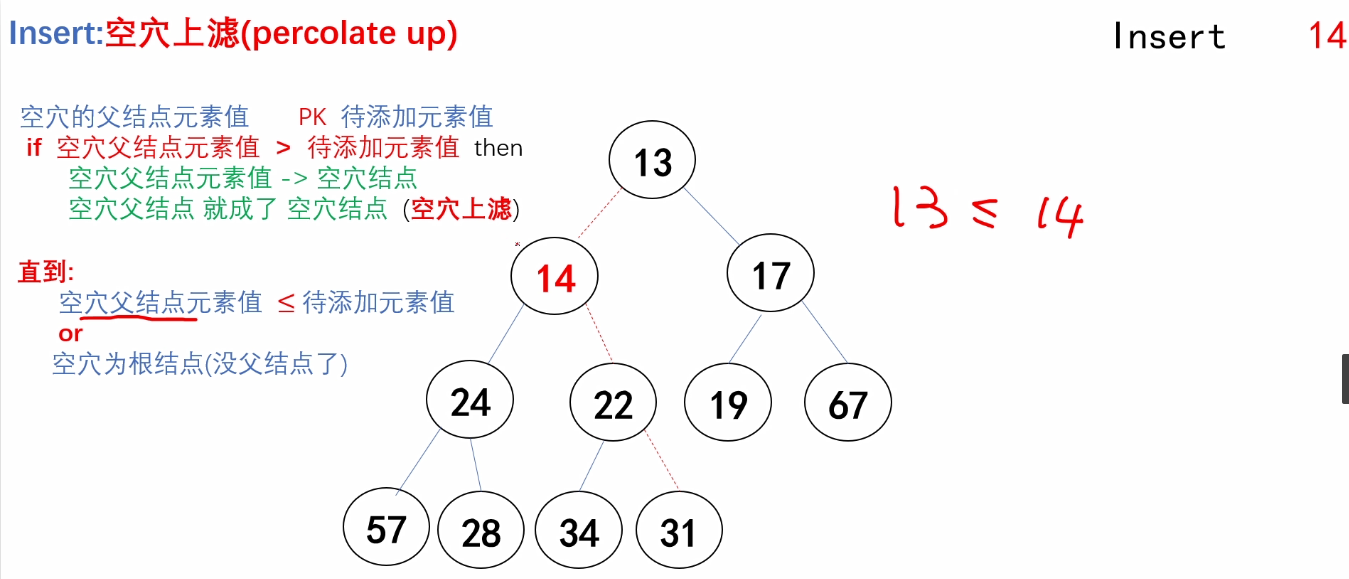
(1)空穴上滤

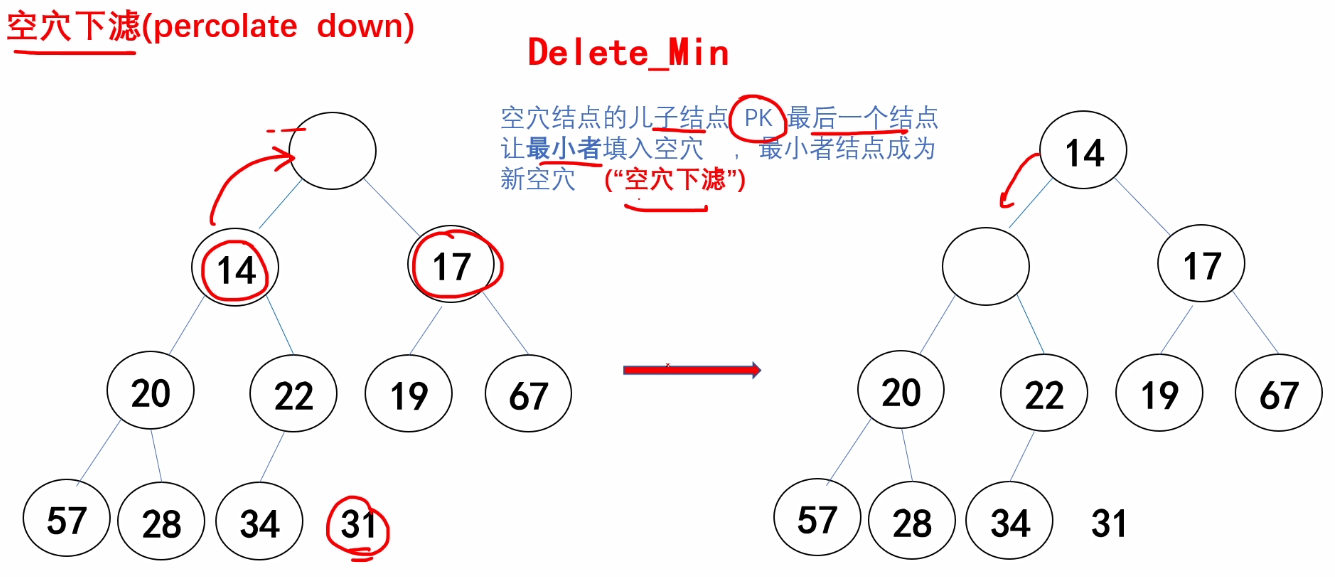
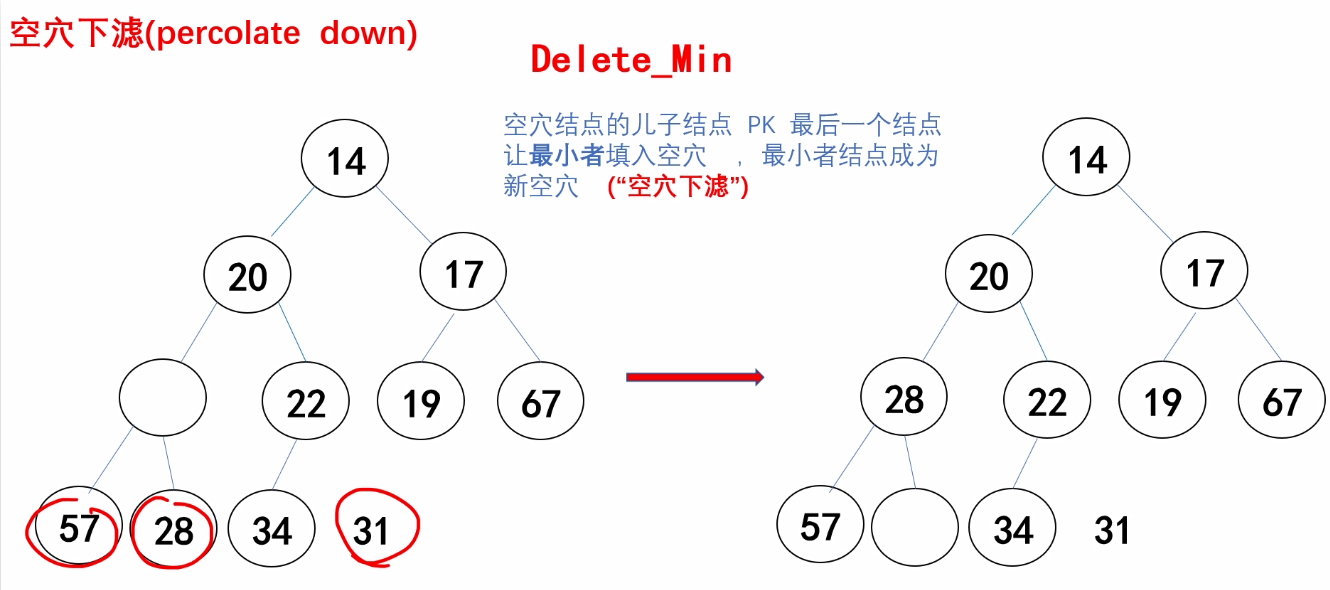
(2)空穴下滤
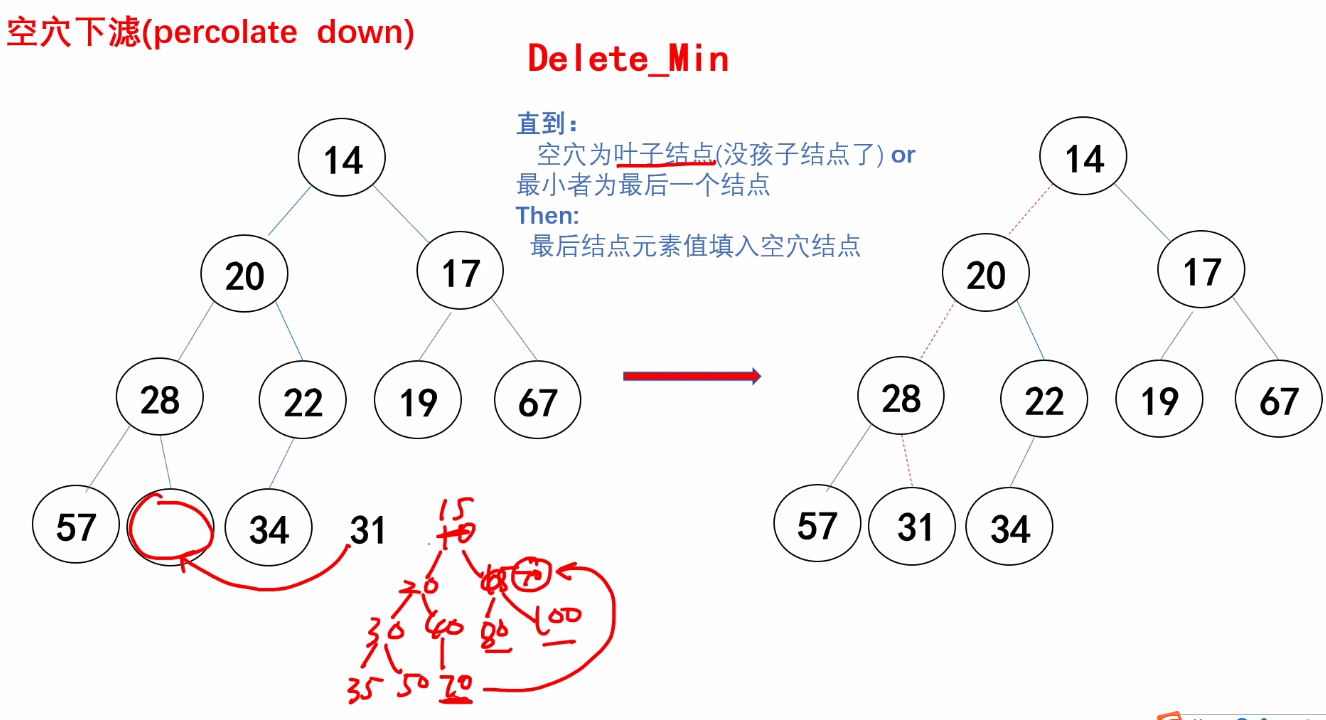
(3)代码实现关键
a.数据类型的实现

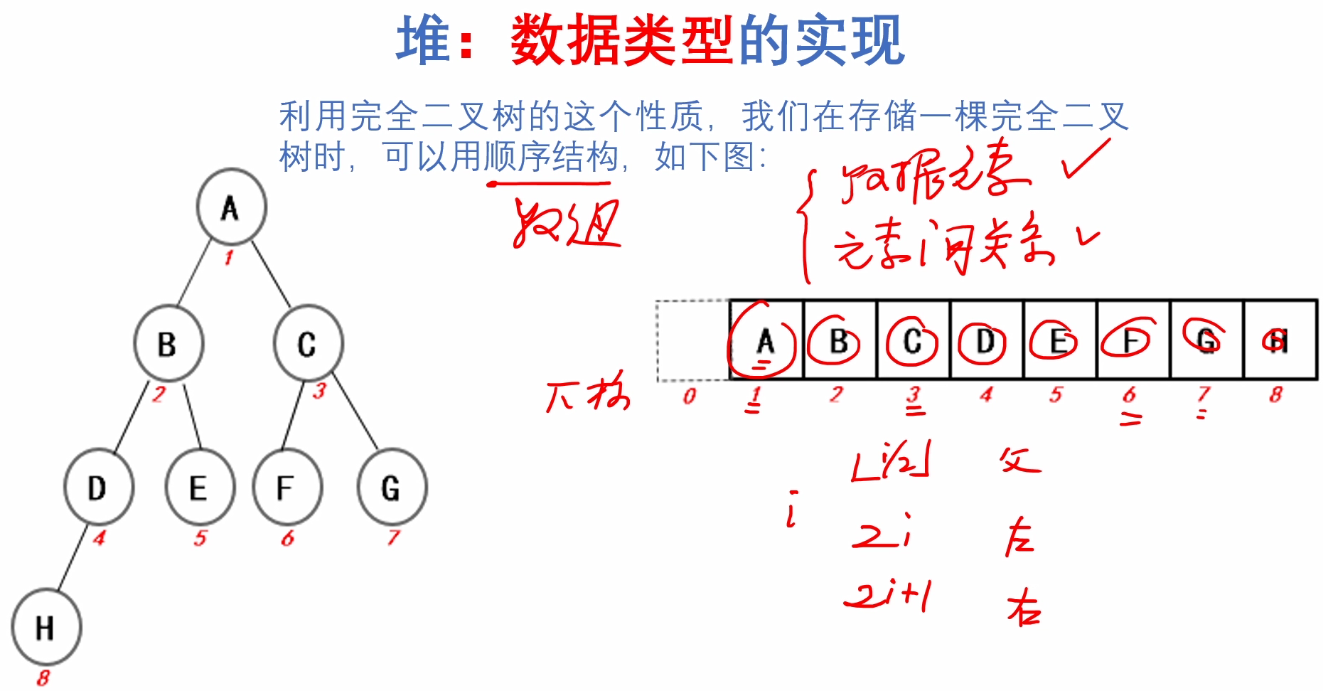
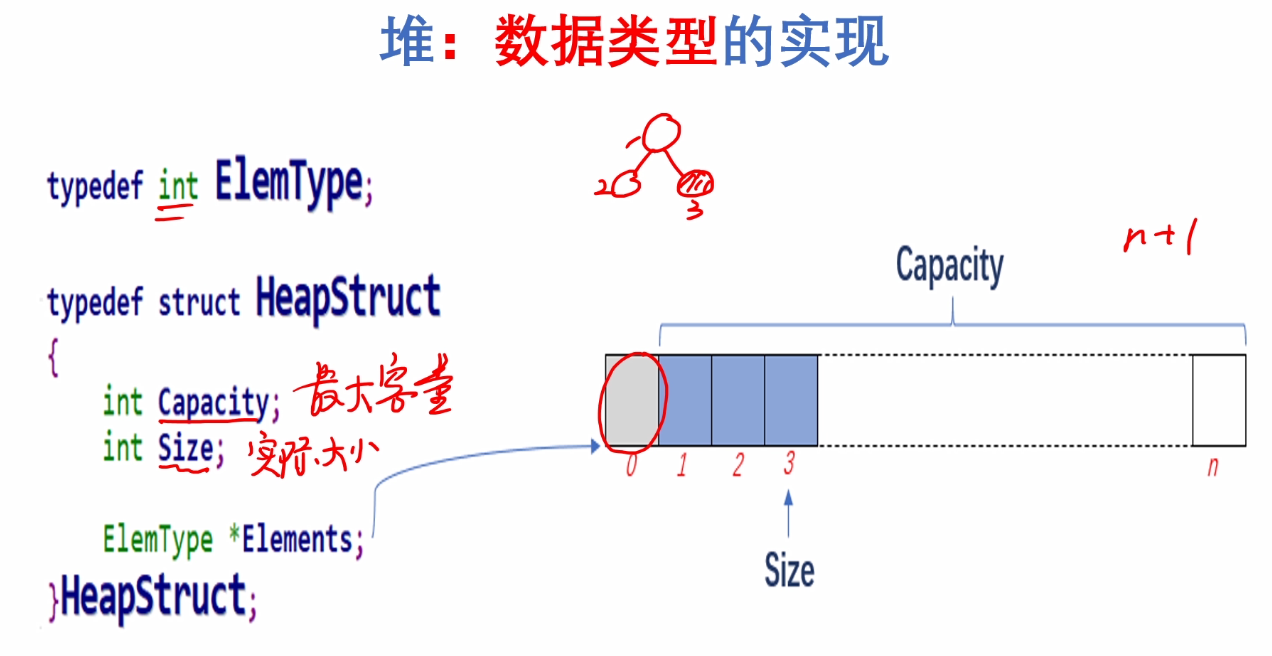
#include <stdio.h>
#include <stdlib.h>
//无穷小
#define VERY_SMALL -1
//堆中结点的数据类型
typedef int ElemType;
typedef struct Heapstruct
{
int Capacity;//堆中的最大容量
int size;//堆中实际的结点数,最后那个结点的编号(下标)
ElemType *Elements;
}HeapStruct;
/*
Init Heap:分配一个堆的结构体
@n:指定堆中最大容量
返回值:
返回分配到的堆的结构体的指针
*/
HeapStruct* Init_Heap(int n)
{
Heapstruct *H= malloc(sizeof(*H));
H->Capacity = n;
H->size = 0;
H->Elements = malloc(sizeof(ElemType)*(n+1));
H->Elements[0] = VERY_SMALL; //??
return H;
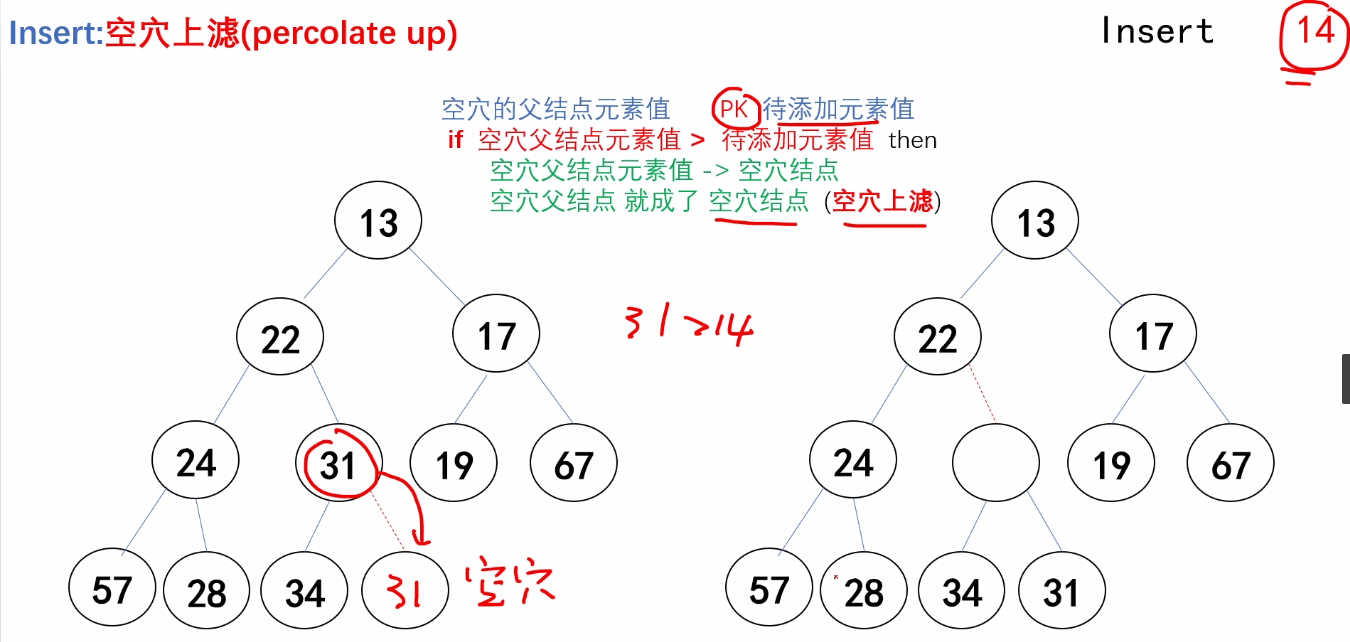
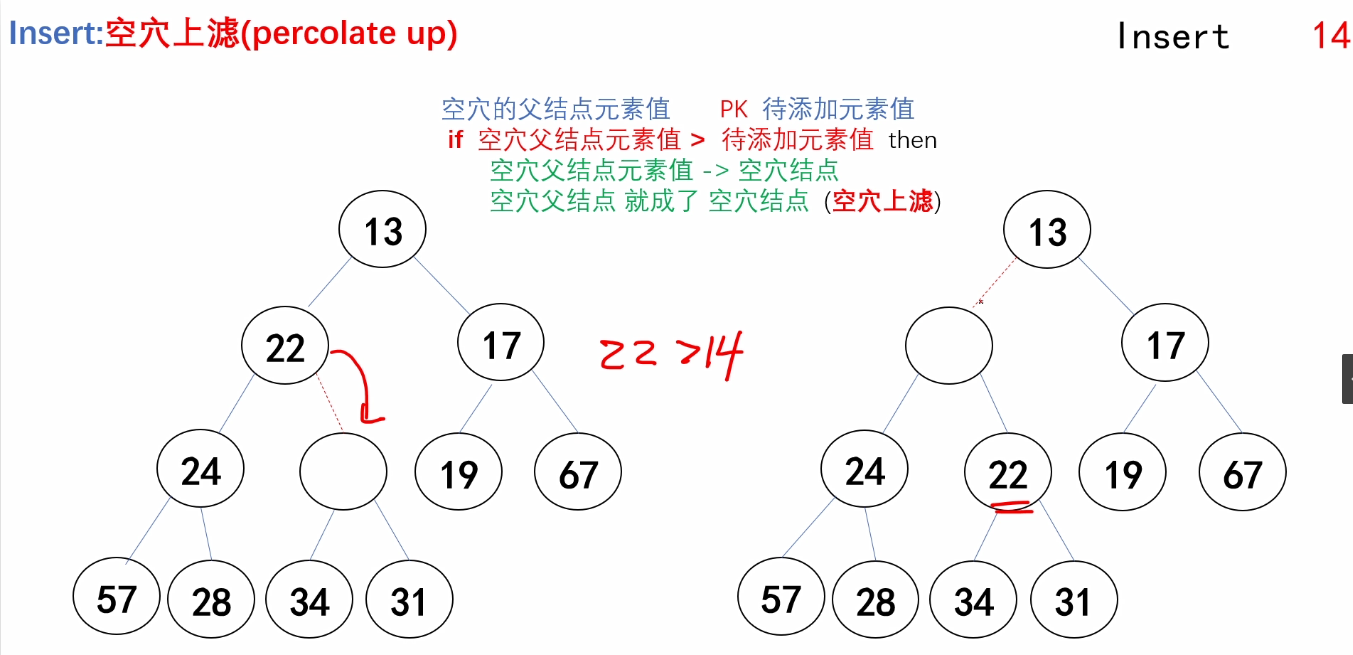
}b.Insert操作的实现
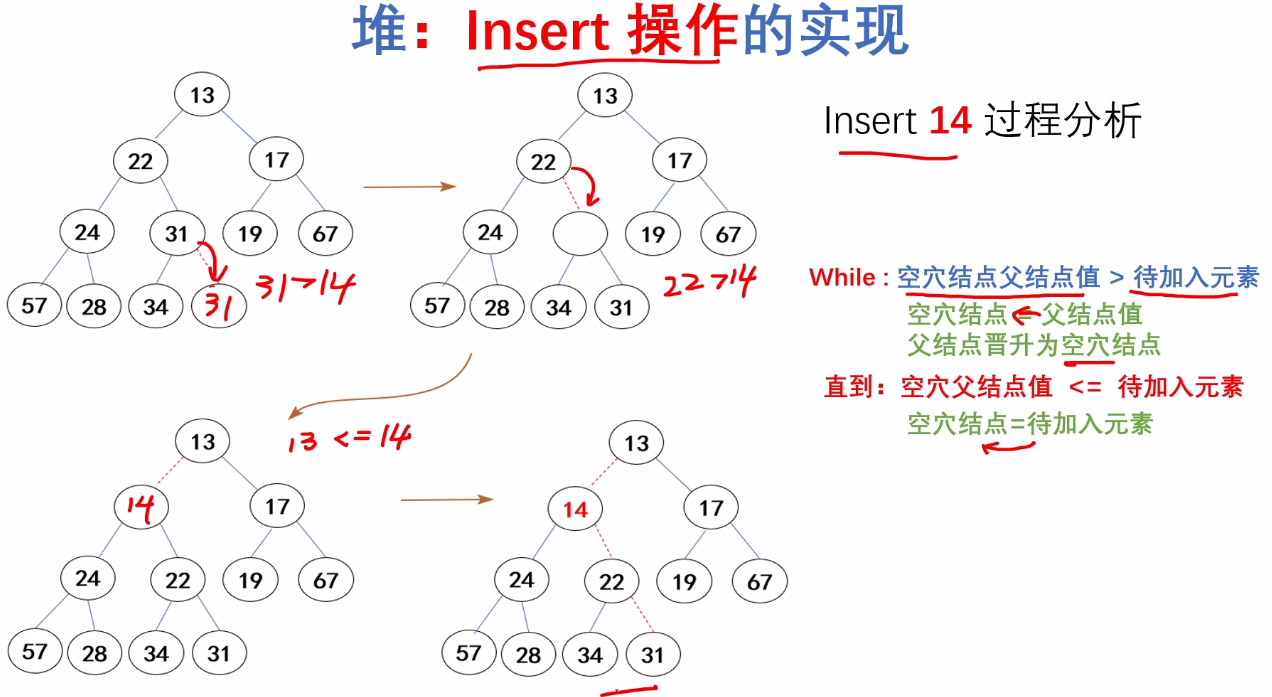
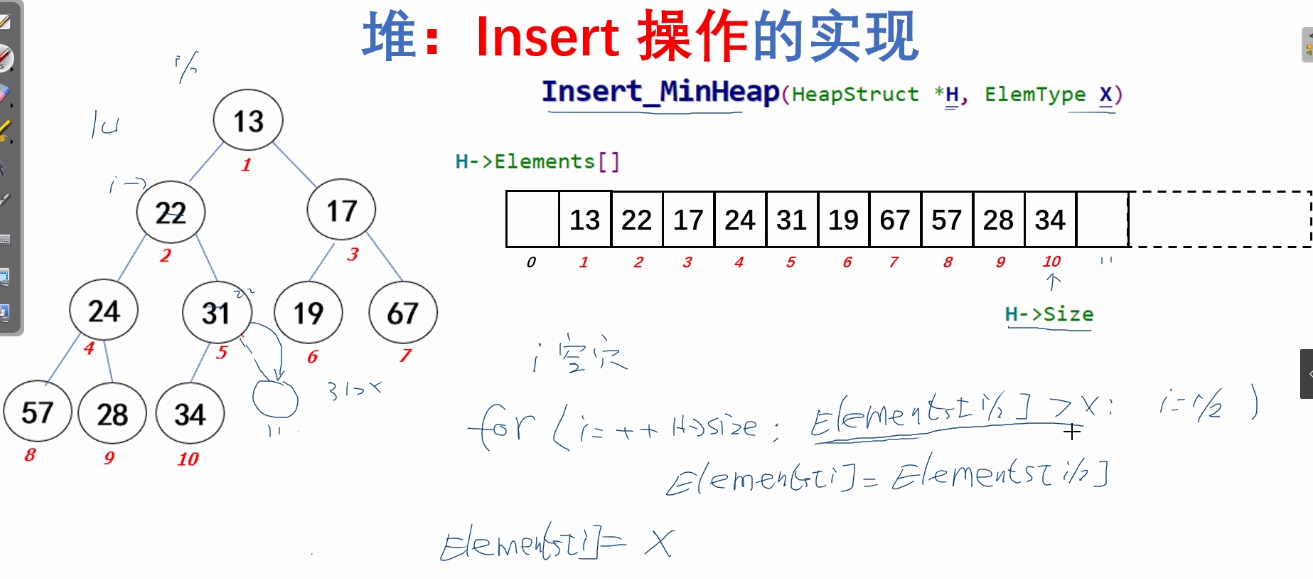
/*
Insert MinHeap:最小堆的插入操作
@H:指向最小堆结构体指针
@X:待插入元素
返回值:
无返回值。
*/
void Insert_MinHeap(Heapstruct *H, ElemType x)
{
int i;//指向空穴结点的下标
for(i = ++H->size; H->Elements[i/2] > x; i = i/2)
{
H->Elements[i] = H->Elements[i/2];
}
H->Elements[i] = x;
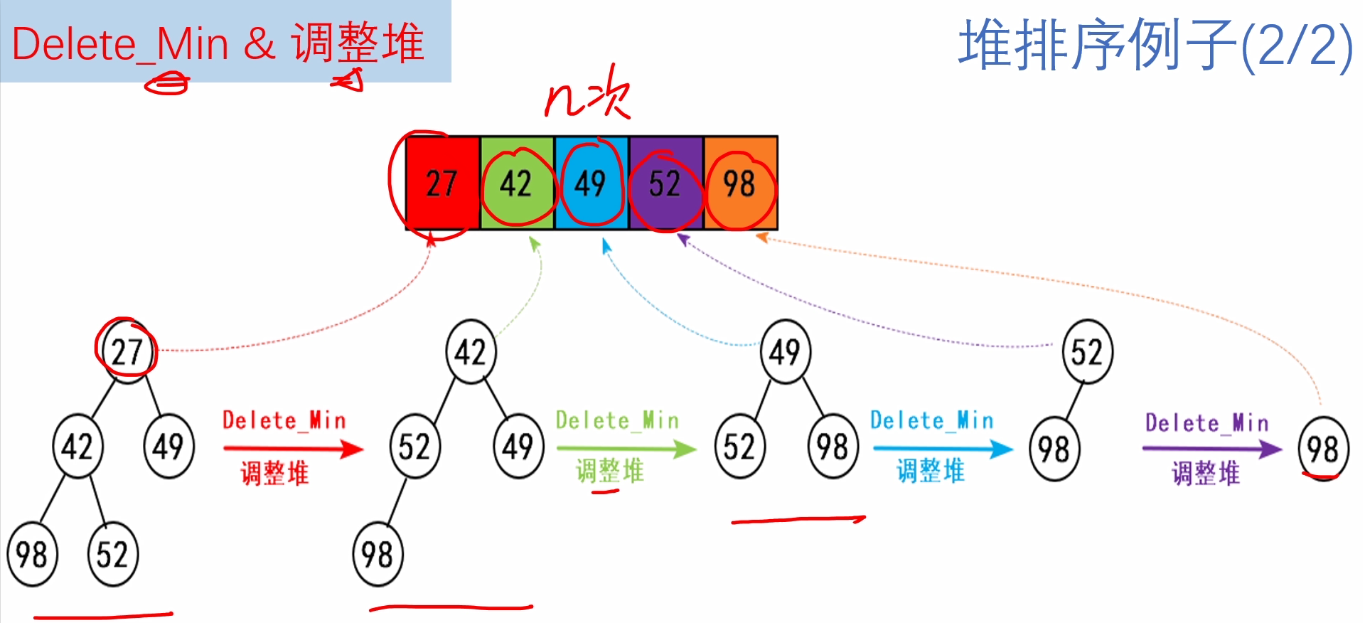
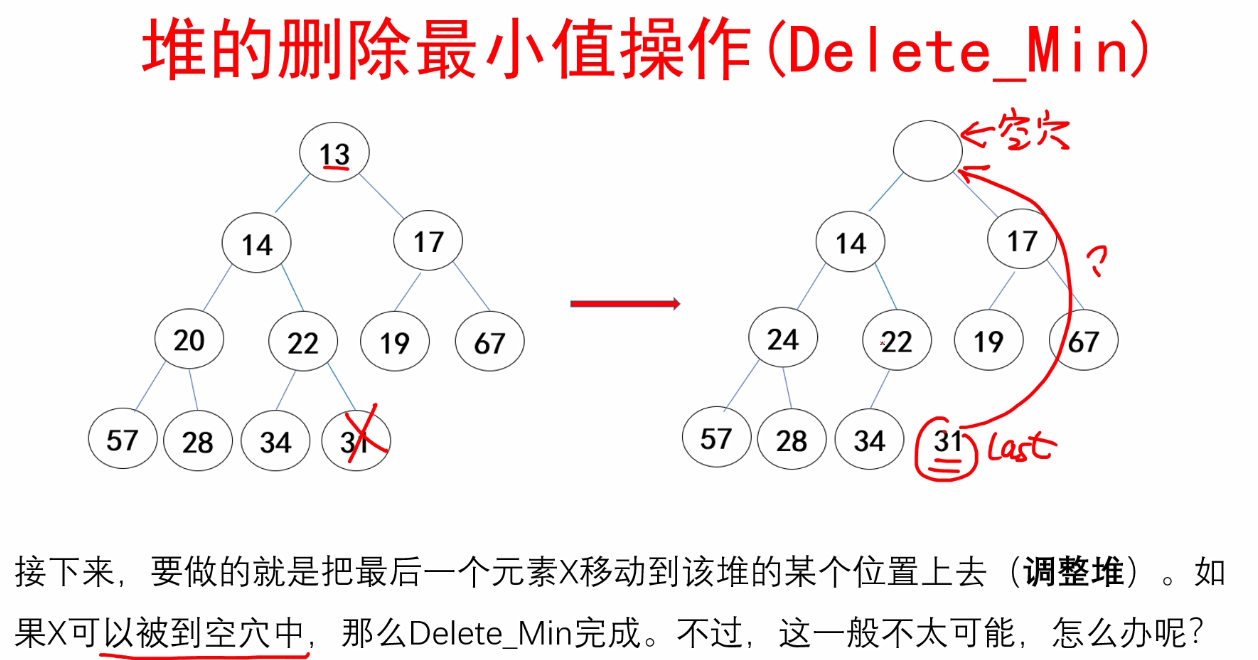
}c.Delete_Min操作的实现
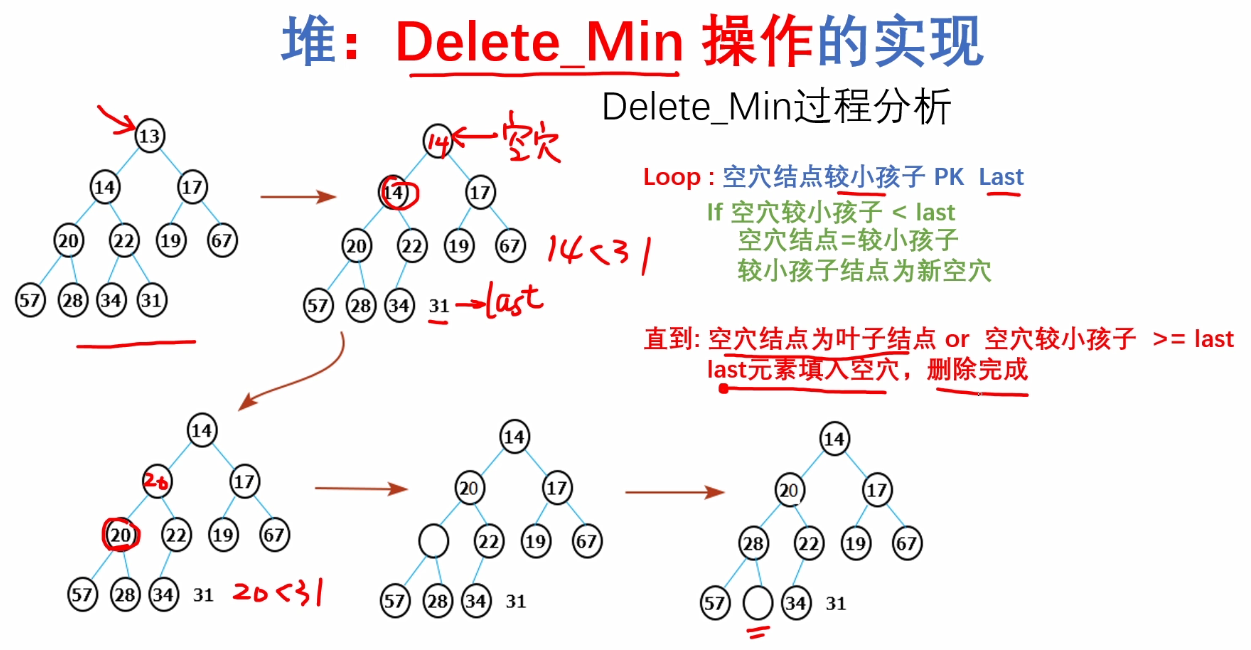
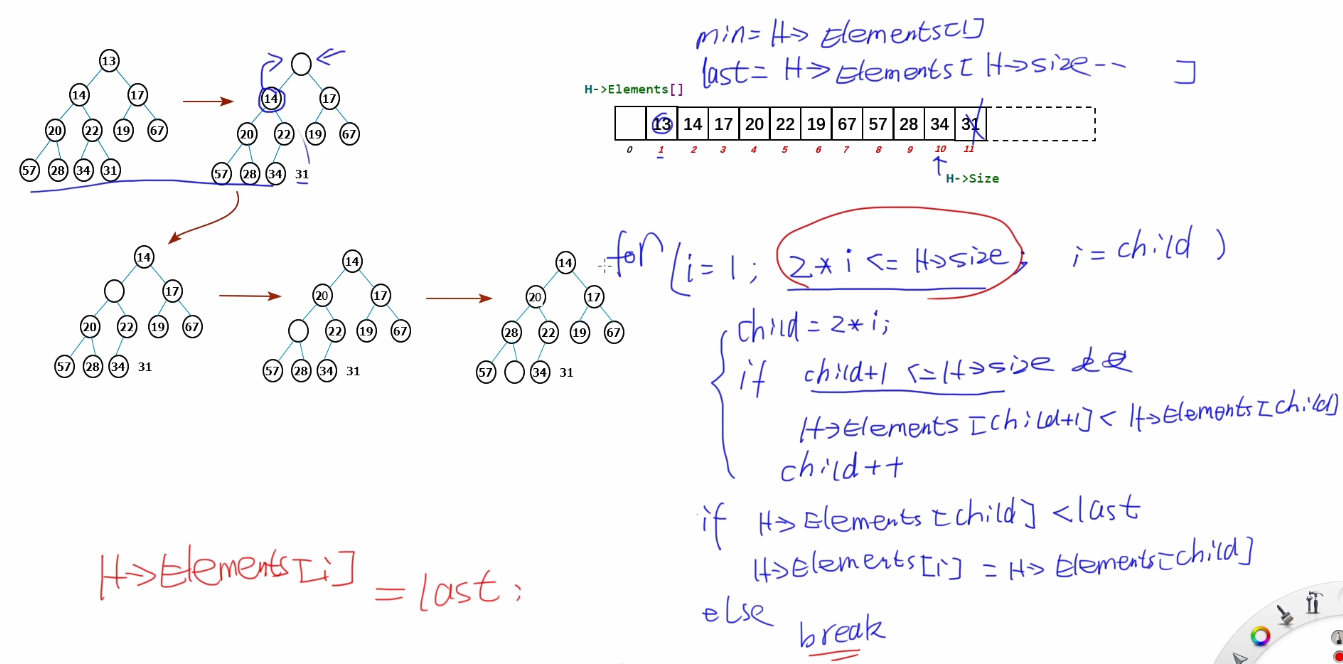
/*
Delete_Min:删除最小堆的最小值并调整使其仍然为最小堆
@H:指向要删除最小值的最小堆
返回值:
返回删除的最小值
*/
ElemType Delete_Min(Heapstruct *H)
{
ElemType min = H->Elements[1];
ElemType last = H->Elements[H->size--];
int i;//指向空穴结点的下标
int child;//指向空穴的较小孩子结点
for(i = 1; 2*i <= H->size; i = child)
{
child = 2*i;
//如果有右孩子 并且 右孩子小于左孩子,child++
if(child + 1 <= H->size &&
H->Elements[child + 1] < H->Elements[child])
{
child++;
}
//将孩子结点与最后一个结点比较,如果小于最后一个结点
//将孩子结点的值给父结点,此时孩子结点为新的空穴结点
if(H->Elements[child] < last)
{
H->Elements[i] = H->Elements[child];
}
else //last比最小的孩子结点还要小
{
break;
}
}
H->Elements[i] = last;
return min;
}d.堆排序代码实现
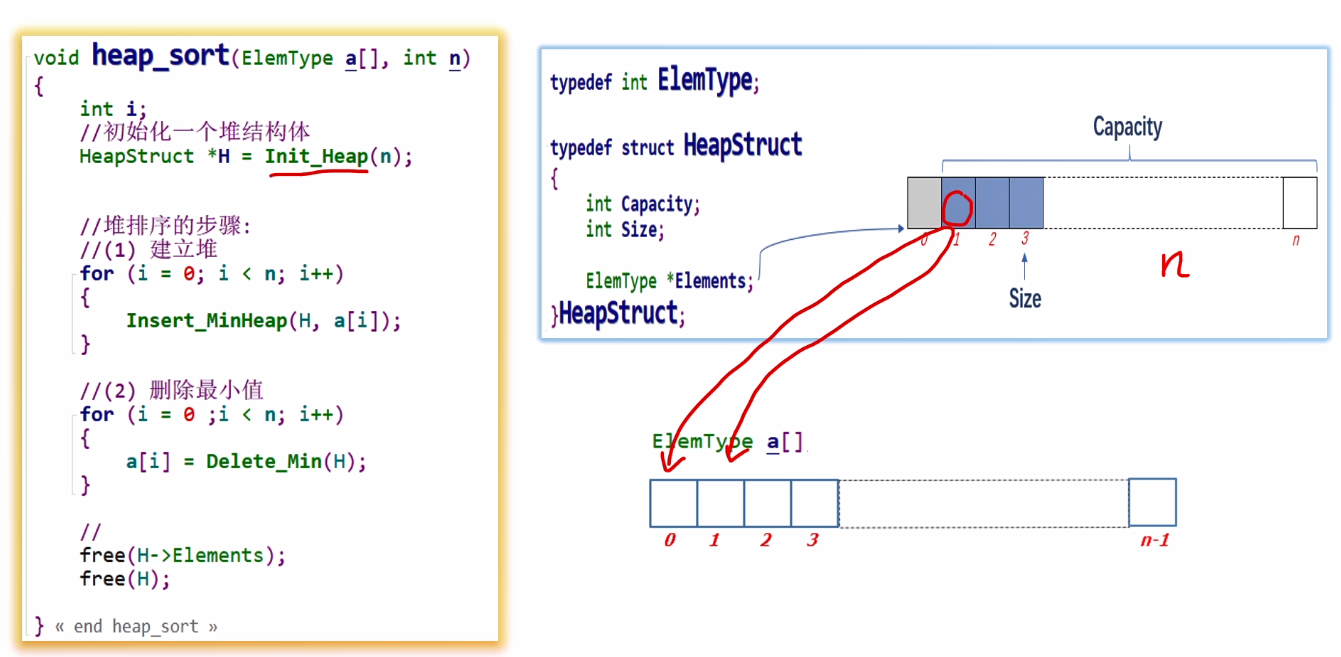
#include <stdio.h>
#include <stdlib.h>
#define N 10
//无穷小
#define VERY_SMALL -1
//堆中结点的数据类型
typedef int ElemType;
typedef struct Heapstruct
{
int Capacity;//堆中的最大容量
int size;//堆中实际的结点数,最后那个结点的编号(下标)
ElemType *Elements;
}HeapStruct;
/*
Init Heap:分配一个堆的结构体
@n:指定堆中最大容量
返回值:
返回分配到的堆的结构体的指针
*/
HeapStruct* Init_Heap(int n)
{
HeapStruct *H= malloc(sizeof(*H));
H->Capacity = n;
H->size = 0;
H->Elements = malloc(sizeof(ElemType)*(n+1));
H->Elements[0] = VERY_SMALL; //??
return H;
}
/*
Insert MinHeap:最小堆的插入操作
@H:指向最小堆结构体指针
@X:待插入元素
返回值:
无返回值。
*/
void Insert_MinHeap(HeapStruct *H, ElemType x)
{
int i;//指向空穴结点的下标
for(i = ++H->size; H->Elements[i/2] > x; i = i/2)
{
H->Elements[i] = H->Elements[i/2];
}
H->Elements[i] = x;
}
/*
Delete_Min:删除最小堆的最小值并调整使其仍然为最小堆
@H:指向要删除最小值的最小堆
返回值:
返回删除的最小值
*/
ElemType Delete_Min(HeapStruct *H)
{
ElemType min = H->Elements[1];
ElemType last = H->Elements[H->size--];
int i;//指向空穴结点的下标
int child;//指向空穴的较小孩子结点
for(i = 1; 2*i <= H->size; i = child)
{
child = 2*i;
//如果有右孩子 并且 右孩子小于左孩子,child++
if(child + 1 <= H->size &&
H->Elements[child + 1] < H->Elements[child])
{
child++;
}
//将孩子结点与最后一个结点比较,如果小于最后一个结点
//将孩子结点的值给父结点,此时孩子结点为新的空穴结点
if(H->Elements[child] < last)
{
H->Elements[i] = H->Elements[child];
}
else //last比最小的孩子结点还要小
{
break;
}
}
H->Elements[i] = last;
return min;
}
/*
heap sort:堆排序
@a:待排序数组
@n:元素个数
返回值:
无
*/
void heap_sort(ElemType a[], int n)
{
int i;
//初始化一个堆结构体
HeapStruct *H = Init_Heap(n);
//堆排序的步骤:
//(1)建立堆
for(i = 0; i < n; i++)
{
Insert_MinHeap(H, a[i]);
}
//(2)删除最小值
for(i = 0; i < n; i++)
{
a[i] = Delete_Min(H);
}
free(H->Elements);
free(H);
}
int main()
{
int i;
int a[N];
for(i = 0; i < N; i++)
{
scanf("%d",&a[i]);
}
heap_sort(a, N);
for(i = 0; i < N; i++)
{
printf("%d\t",a[i]);
}
return 0;
}e.堆排序In-place版本实现
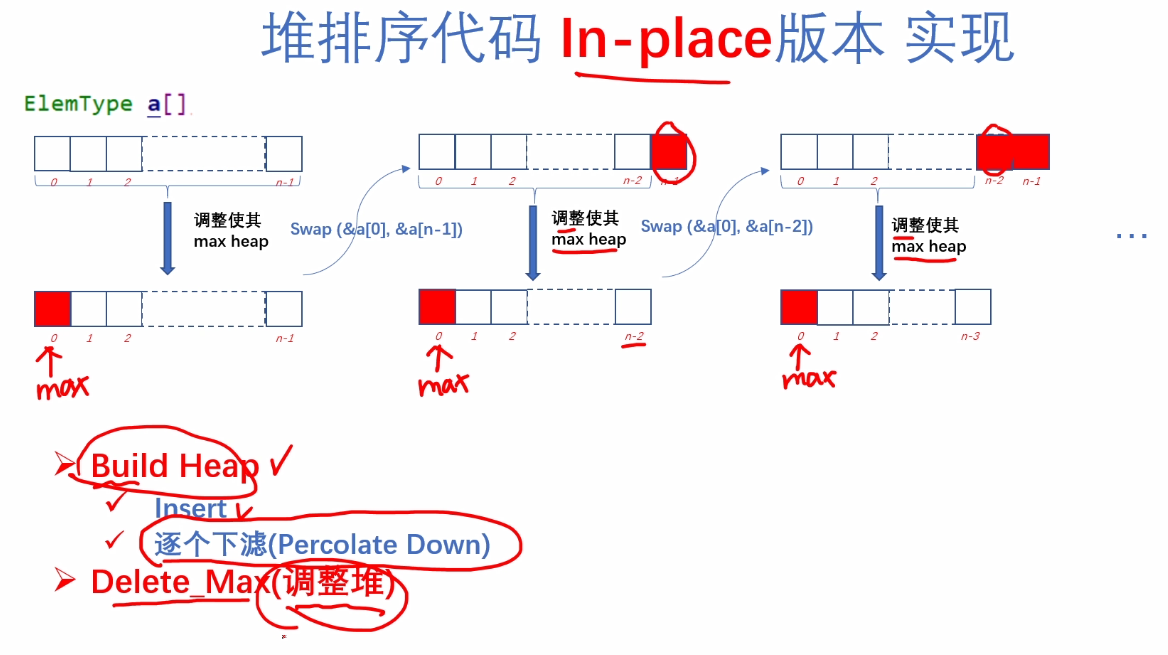

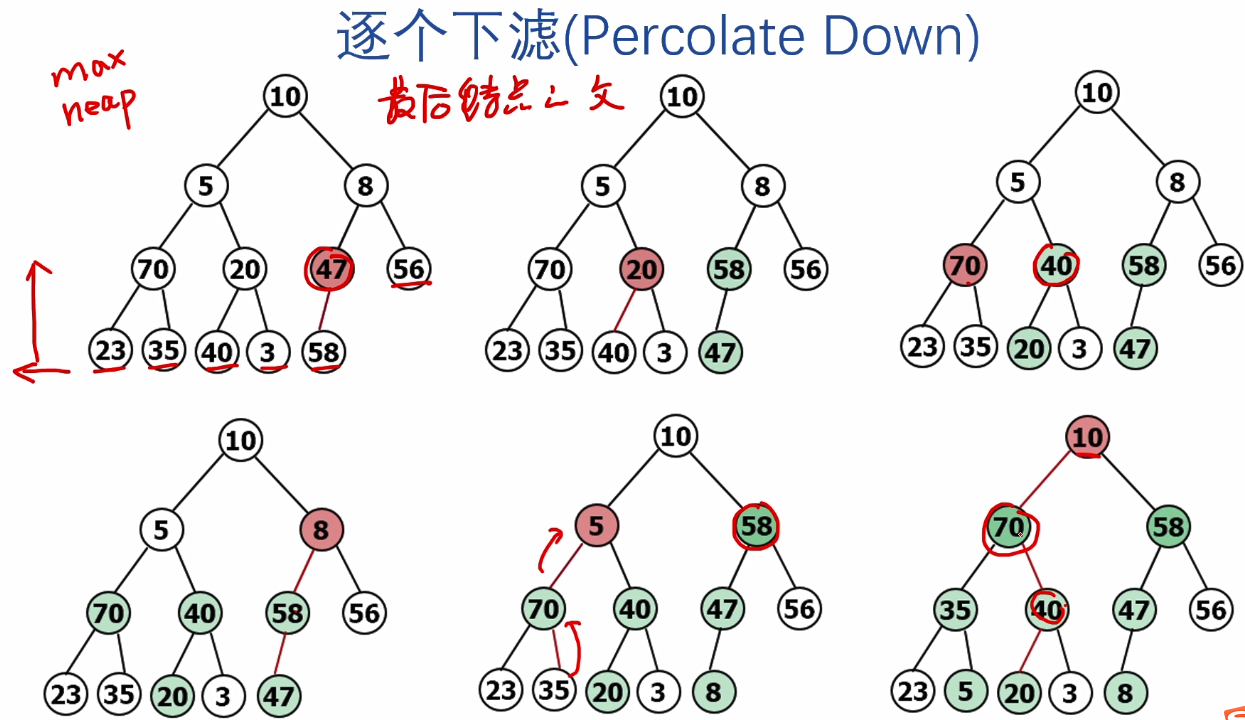
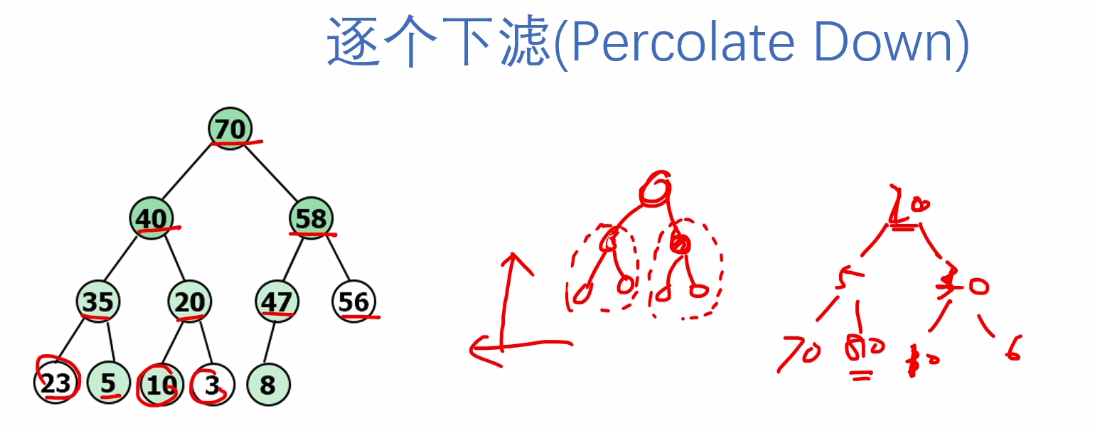
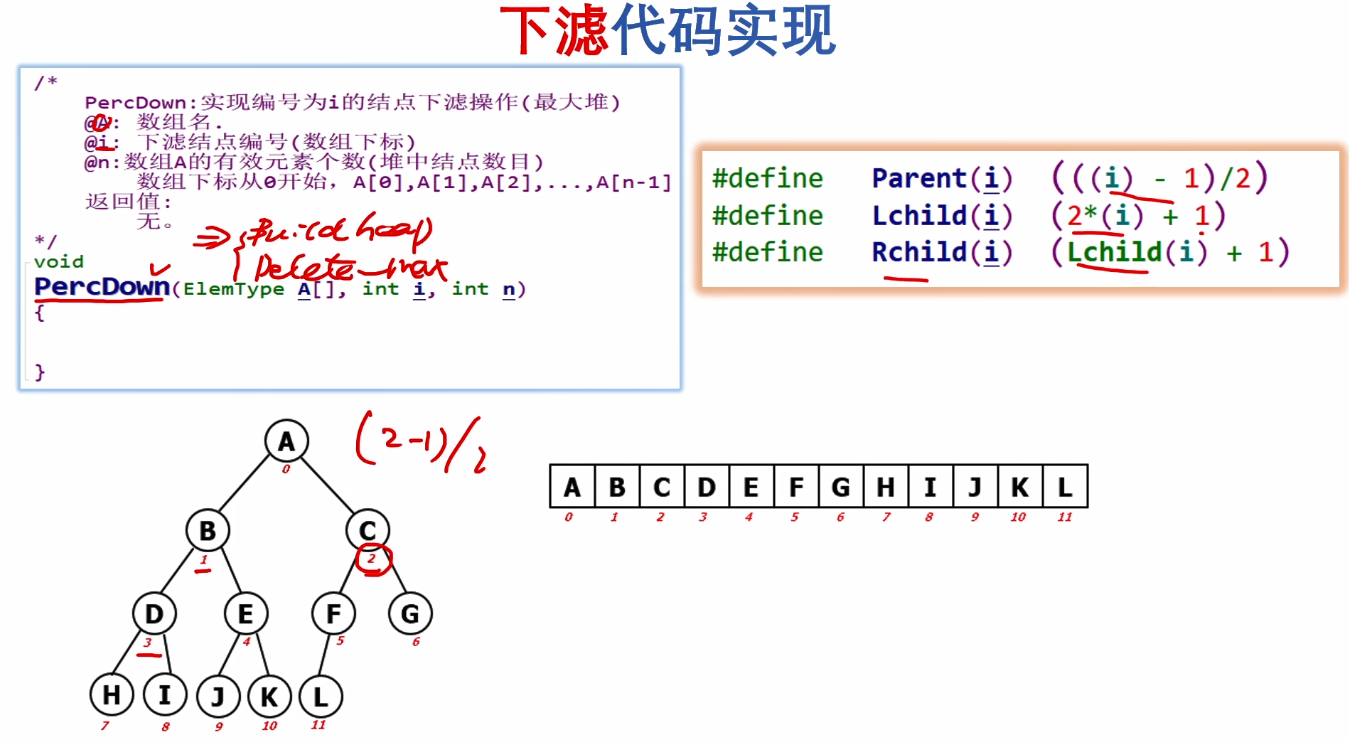
#include <stdio.h>
#include <stdlib.h>
#define N 5
#define Parent(i) (((i) - 1)/2)
#define Lchild(i) (2*(i) + 1)
#define Rchild(i) (Lchild(i) + 1)
//堆中结点的数据类型
typedef int ElemType;
void swap(int *p,int *s)
{
int t;
t = *p;
*p = *s;
*s = t;
}
/*
PercDown:实现编号为i的结点下滤操作(最大堆)
@A:数组名
@i:下滤结点编号(数组下标)
@n:数组A的有效元素个数(堆中结点数目)
数组下标从开始,A[0],A[1],A[2],...A[n-1]
返回值:
无
*/
void PercDown(ElemType A[], int i, int n)
{
int child;//指向空穴结点的较大孩子结点
ElemType tmp;//保存空穴结点的元素值
for(tmp = A[i]; Lchild(i) < n; i = child)
{
child = Lchild(i);
if(child + 1 < n && A[child + 1] > A[child])
{
child++;
}
if(A[child] > tmp)
{
A[i] = A[child];
}
else //tmp>= A[child]
{
break;
}
}
A[i] = tmp;
}
void heap_sort_v2(ElemType A[], int n)
{
int i;//下滤结点下标
//1. build max heap
//逐个下滤
//建立最大堆
for(i = Parent(n-1); i >= 0; i--)
{
PercDown( A, i, n);
}
//2.Delete_MAX
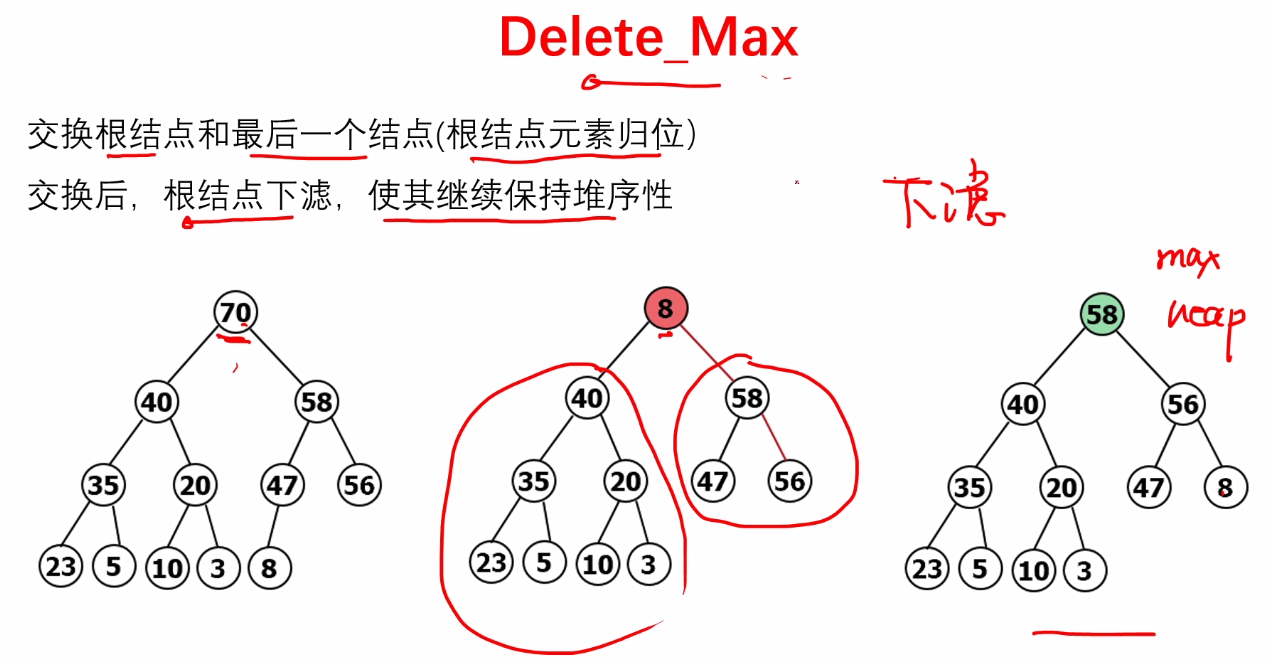
for(i = n-1; i > 0; i--)
{
swap(&A[0], &A[i]);
PercDown( A, 0, i);
}
}
int main()
{
int i;
int a[N];
for(i = 0; i < N; i++)
{
scanf("%d",&a[i]);
}
heap_sort_v2(a, N);
for(i = 0; i < N; i++)
{
printf("%d\t",a[i]);
}
return 0;
}3.堆排序的性能分析
(1)时间复杂度

(2)空间复杂度
O(1)
4.堆排序稳定性分析
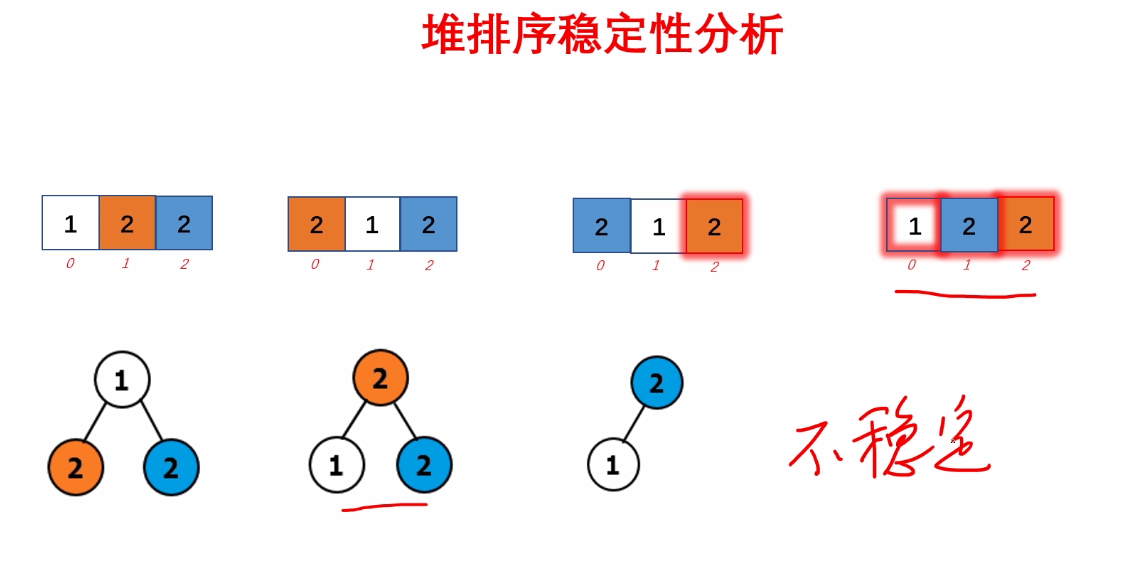
5.总结
适用场景
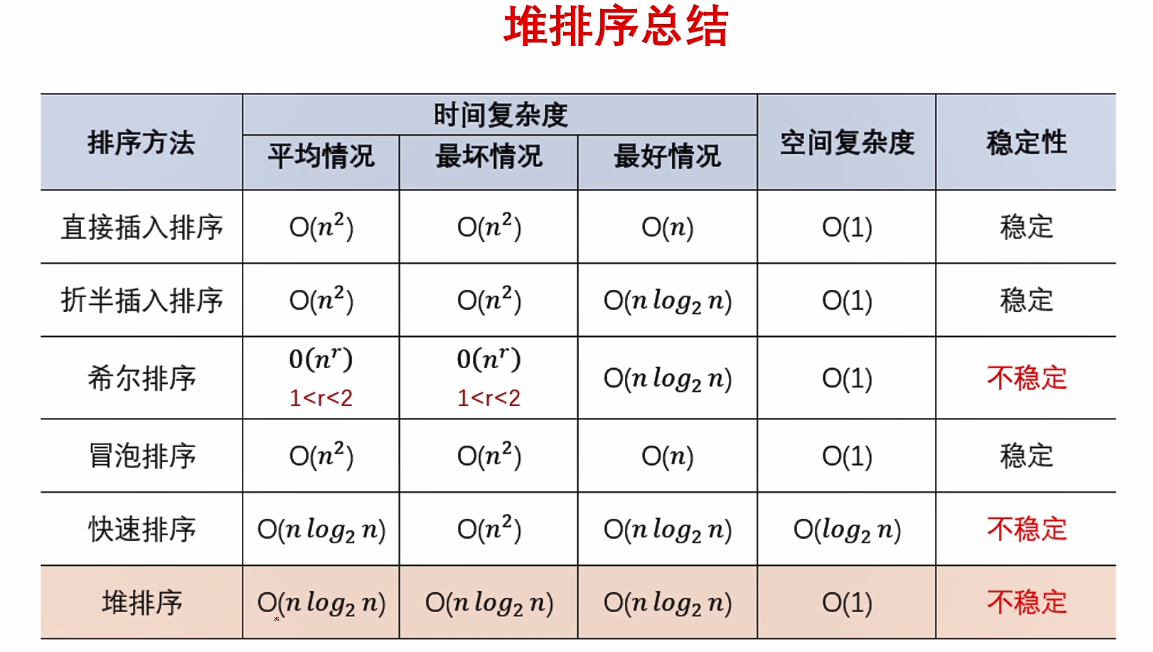
堆排序在建立堆和调整堆的过程中会产生比较大的开销,在元素少的时候并不适用。但是,在元素比较多的情况下,还是不错的一个选择。尤其是在解决诸如“前n大的数”一类问题时,几乎是首选算法。
九.归并排序
1.什么是归并排序
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。
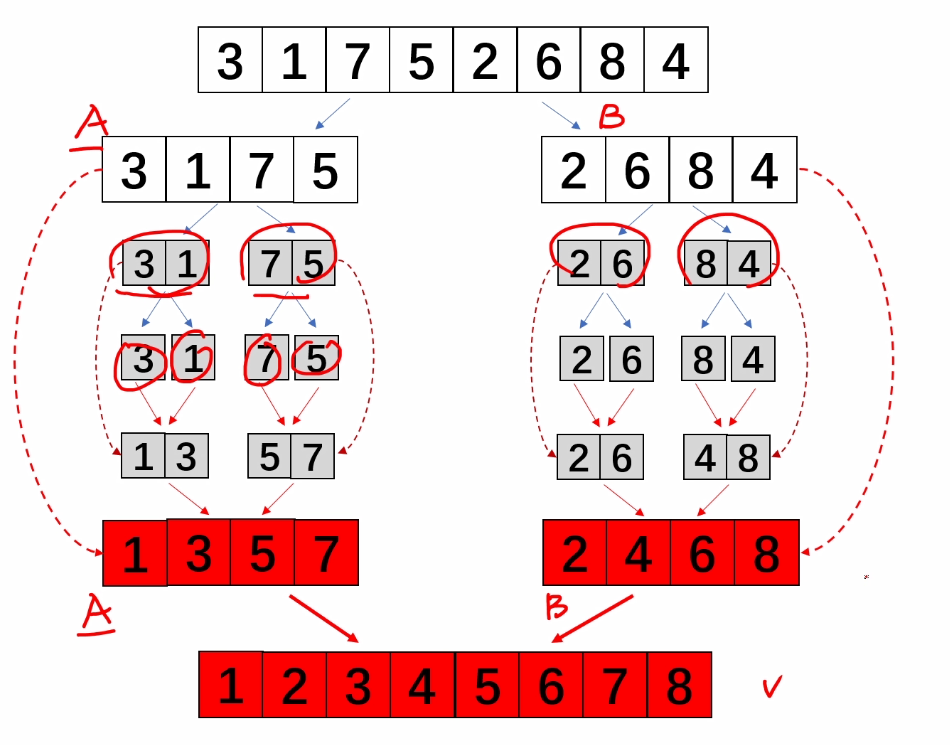
2.算法思路
- 把长度为n的输入序列分成两个长度为n/2的子序列;
- 对这两个子序列分别采用归并排序;
- 将两个排序好的子序列合并成一个最终的排序序列。

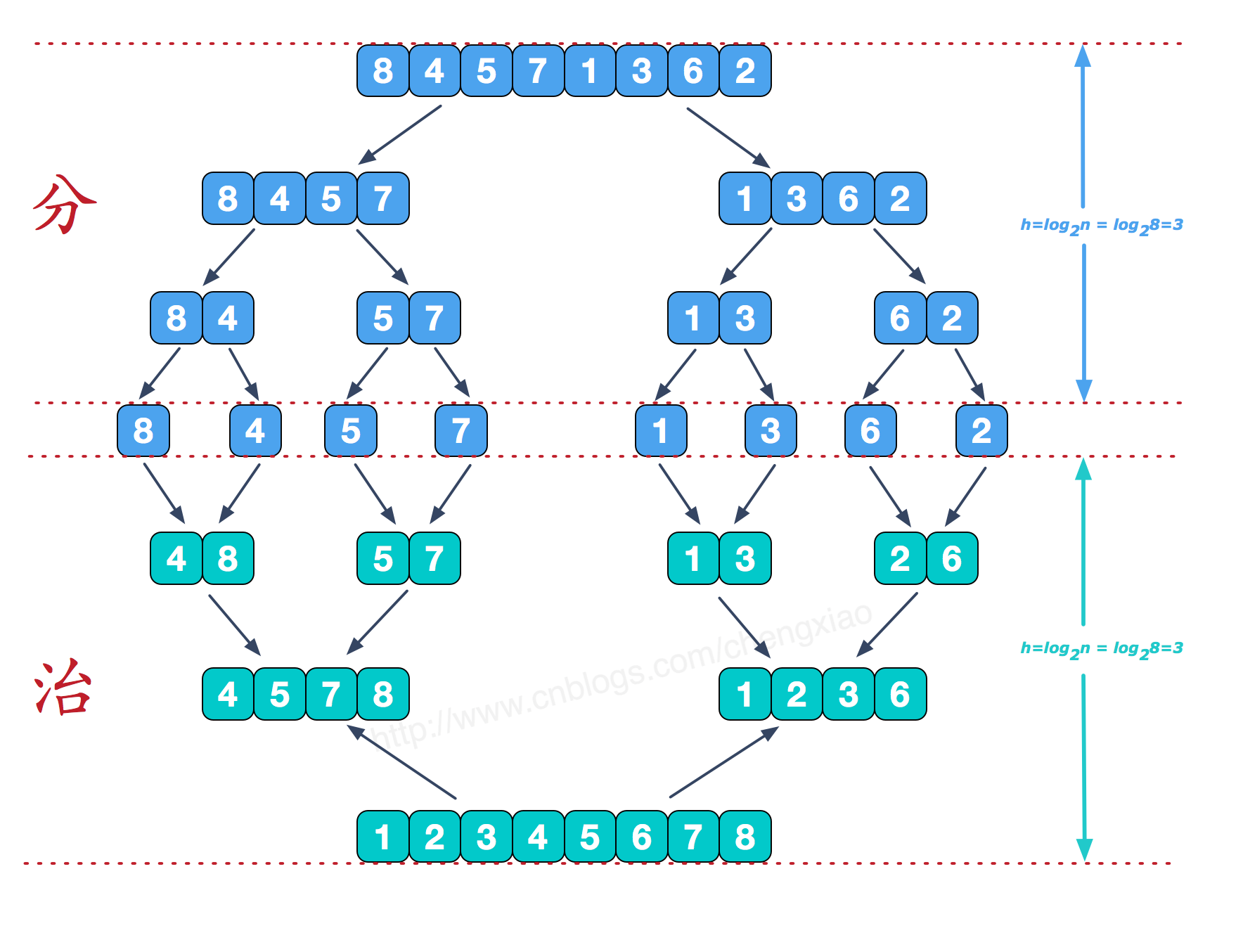
可以看到这种结构很像一棵完全二叉树,本文的归并排序我们采用递归去实现(也可采用迭代的方式去实现)。分阶段可以理解为就是递归拆分子序列的过程,递归深度为log2n。
合并相邻有序子序列
再来看看治阶段,我们需要将两个已经有序的子序列合并成一个有序序列,比如上图中的最后一次合并,要将[4,5,7,8]和[1,2,3,6]两个已经有序的子序列,合并为最终序列[1,2,3,4,5,6,7,8],来看下实现步骤。
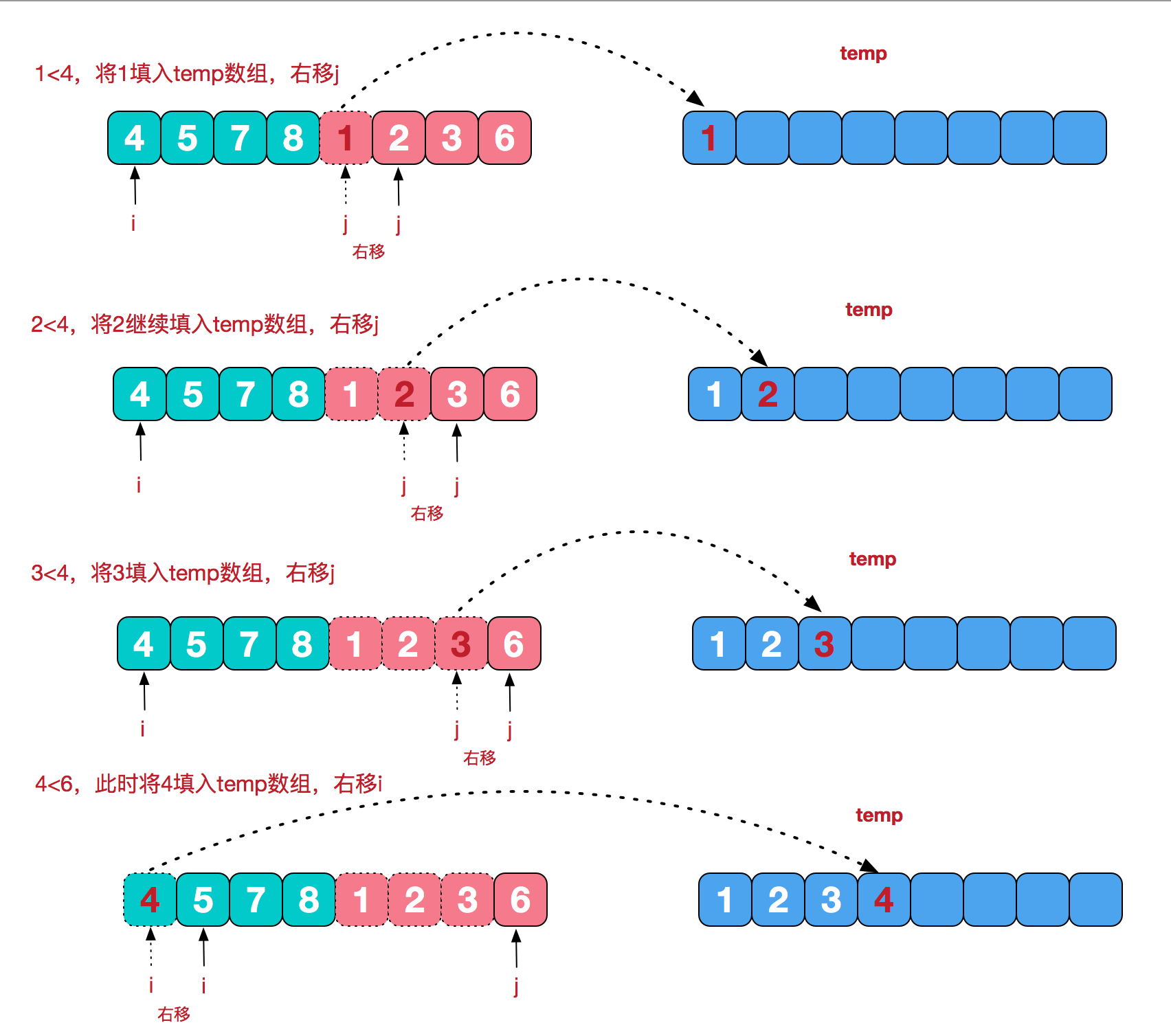
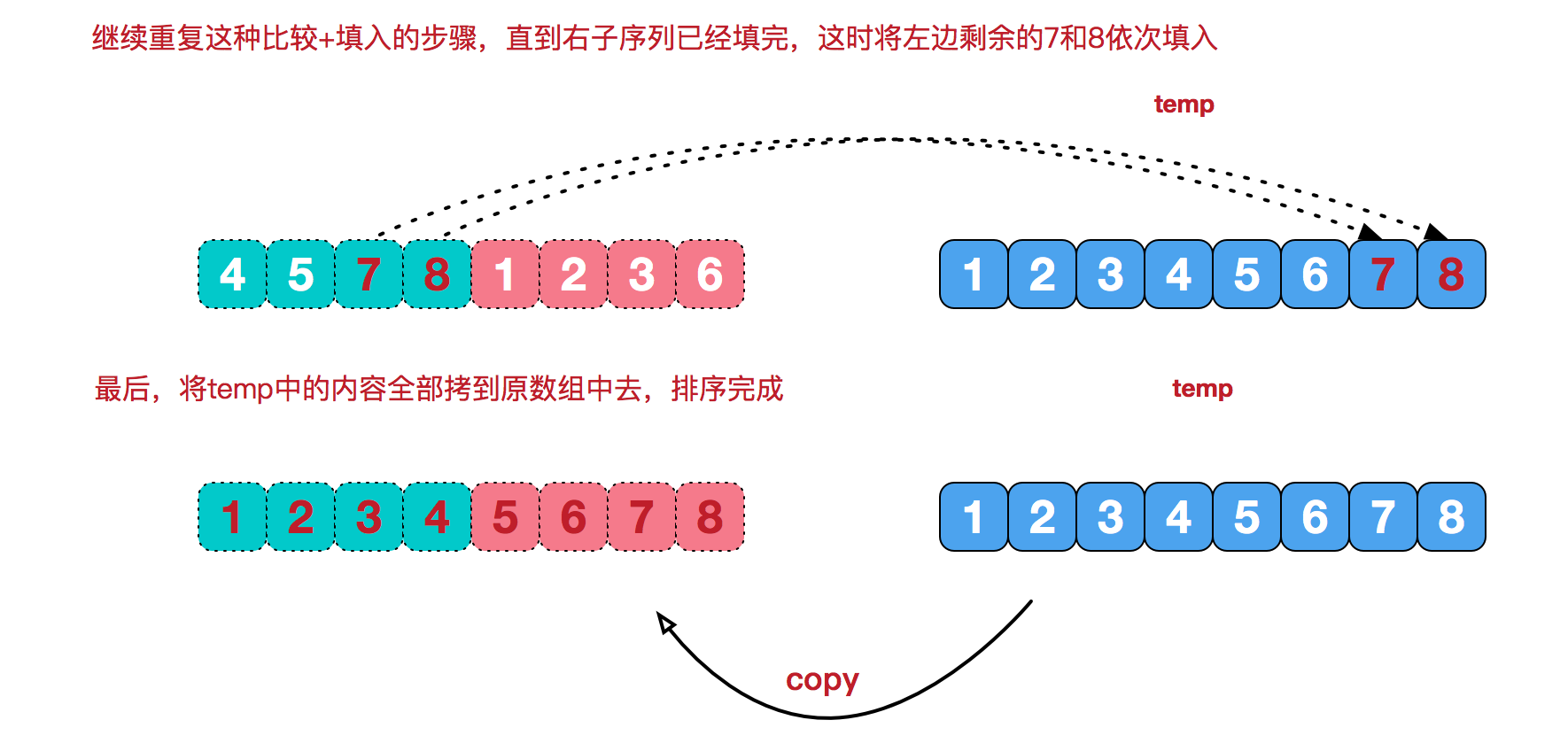
代码实现
#include <stdio.h>
#include <stdlib.h>
#define N 5
typedef int ElemType;
/*
Merge:对两个有序表
S[Lpos].. S[Rpos-1]
S[Rpos].. S[RightEnd]
进行归并操作
@s:数组
@Lpos:左边有序表开始元素的下标
@Rpos:右边有序表开始元素的下标
@RightEnd:右边有序表最后元素的下标
@Aux:辅助数组
返回值:
无
*/
void Merge(ElemType s[], int Lpos, int Rpos, int RightEnd,
ElemType Aux[])
{
int LeftEnd = Rpos - 1;
int Num = RightEnd - Lpos + 1;//要归并的总共的元素个数
int C_pos = Lpos;//辅助数组的起始下标
while(Lpos <= LeftEnd && Rpos <= RightEnd)
{
if(s[Lpos] <= s[Rpos])
{
Aux[C_pos++] = s[Lpos++];
}
else
{
Aux[C_pos++] = s[Rpos++];
}
}
//右边那个序列先到末尾
while(Lpos <= LeftEnd)
{
Aux[C_pos++] = s[Lpos++];
}
while(Rpos <= RightEnd)
{
Aux[C_pos++] = s[Rpos++];
}
int i=0;//拷贝次数
for(i = 0; i < Num; RightEnd--,i++)
{
s[RightEnd] = Aux[RightEnd];
}
}
/*
MSort:对数列进行归并排序
@s:要进行归并排序的数组
@Left:归并排序最左边元素的下标
@Right:归并排序最右边元素的下标
@Aux:辅助数组
返回值:
无。
*/
void Msort(ElemType s[], int Left, int Right, ElemType Aux[])
{
if(Left < Right)
{
//1.分割
int mid = (Left + Right) / 2;
//A: Left ... mid
//B: mid+1 ... Rught
//2.对A进行归并排序
Msort(s, Left, mid, Aux);
//3.对B进行归并排序
Msort(s, mid+1, Right, Aux);
//4.对A和B进行归并操作
Merge(s, Left, mid+1, Right, Aux);
}
}
void Merge_Sort(ElemType A[], int n)
{
ElemType *Aux = malloc(sizeof(ElemType) *n);
Msort(A, 0, n-1, Aux);
free(Aux);
}
int main()
{
int i;
int a[N];
for(i = 0; i < N; i++)
{
scanf("%d",&a[i]);
}
Merge_Sort(a, N);
for(i = 0; i < N; i++)
{
printf("%d\t",a[i]);
}
printf("\n");
return 0;
}
3.归并排序的性能分析
(1)时间复杂度

(2)空间复杂度
O(n)
4.归并排序稳定性分析

5.总结
适用场景
归并排序在数据量比较大的时候也有较为出色的表现(效率上),但是,其空间复杂度O(n)使得在数据量特别大的时候(例如,1千万数据)几乎不可接受。而且,考虑到有的机器内存本身就比较小,因此,采用归并排序一定要注意。